Анализ больших объемов данных. Big Data и блокчейн — прорыв в области анализа данных
Обычно, когда говорят о серьезной аналитической обработке, особенно если используют термин Data Mining, подразумевают, что данных огромное количество. В общем случае это не так, т. к. довольно часто приходится обрабатывать небольшие наборы данных, и находить в них закономерности ничуть не проще, чем в сотнях миллионов записей. Хотя нет сомнений, что необходимость поиска закономерностей в больших базах данных усложняет и без того нетривиальную задачу анализа.
Такая ситуация особенно характерна для бизнеса, связанного с розничной торговлей, телекоммуникациями, банками, интернетом. В их базах данных аккумулируется огромное количество информации, связанной с транзакциями: чеки, платежи, звонки, логи и т.п.
Не существует универсальных способов анализа или алгоритмов, пригодных для любых случаев и любых объемов информации. Методы анализа данных существенно отличаются друг от друга по производительности, качеству результатов, удобству применения и требованиям к данным. Оптимизация может производиться на различных уровнях: оборудование, базы данных, аналитическая платформа, подготовка исходных данных, специализированные алгоритмы. Анализ большого объема данных требует особого подхода, т.к. технически сложно их переработать при помощи только "грубой силы", т.е. использования более мощного оборудования.
Конечно, можно увеличить скорость обработки данных за счет более производительного оборудования, тем более, что современные сервера и рабочие станции используют многоядерные процессоры, оперативную память значительных размеров и мощные дисковые массивы. Однако, есть множество других способов обработки больших объемов данных, которые позволяют повысить масштабируемость и не требуют бесконечного обновления оборудования.
Возможности СУБД
Современные базы данных включают различные механизмы, применение которых позволит значительно увеличить скорость аналитической обработки:
- Предварительный обсчет данных. Сведения, которые чаще всего используются для анализа, можно заранее обсчитать (например, ночью) и в подготовленном для обработки виде хранить на сервере БД в виде многомерных кубов, материализованных представлений, специальных таблиц.
- Кэширование таблиц в оперативную память. Данные, которые занимают немного места, но к которым часто происходит обращение в процессе анализа, например, справочники, можно средствами базы данных кэшировать в оперативную память. Так во много раз сокращаются обращения к более медленной дисковой подсистеме.
- Разбиение таблиц на разделы и табличные пространства. Можно размещать на отдельных дисках данные, индексы, вспомогательные таблицы. Это позволит СУБД параллельно считывать и записывать информацию на диски. Кроме того, таблицы могут быть разбиты на разделы (partition) таким образом, чтобы при обращении к данным было минимальное количество операций с дисками. Например, если чаще всего мы анализируем данные за последний месяц, то можно логически использовать одну таблицу с историческими данными, но физически разбить ее на несколько разделов, чтобы при обращении к месячным данным считывался небольшой раздел и не было обращений ко всем историческим данным.
Это только часть возможностей, которые предоставляют современные СУБД. Повысить скорость извлечения информации из базы данных можно и десятком других способов: рациональное индексирование, построение планов запросов, параллельная обработка SQL запросов, применение кластеров, подготовка анализируемых данных при помощи хранимых процедур и триггеров на стороне сервера БД и т.п. Причем многие из этих механизмов можно использовать с применением не только "тяжелых" СУБД, но и бесплатных баз данных.
Комбинирование моделей
Возможности повышения скорости не сводятся только к оптимизации работы базы данных, многое можно сделать при помощи комбинирования различных моделей. Известно, что скорость обработки существенно связана со сложностью используемого математического аппарата. Чем более простые механизмы анализа используются, тем быстрее данные анализируются.
Возможно построение сценария обработки данных таким образом, чтобы данные "прогонялись" через сито моделей. Тут применяется простая идея: не тратить время на обработку того, что можно не анализировать.
Вначале используются наиболее простые алгоритмы. Часть данных, которые можно обработать при помощи таких алгоритмов и которые бессмысленно обрабатывать с использованием более сложных методов, анализируется и исключается из дальнейшей обработки. Оставшиеся данные передаются на следующий этап обработки, где используются более сложные алгоритмы, и так далее по цепочке. На последнем узле сценария обработки применяются самые сложные алгоритмы, но объем анализируемых данных во много раз меньше первоначальной выборки. В результате общее время, необходимое для обработки всех данных, уменьшается на порядки.
Приведем практический пример использования этого подхода. При решении задачи прогнозирования спроса первоначально рекомендуется провести XYZ-анализ, который позволяет определить, насколько стабилен спрос на различные товары. Товары группы X продаются достаточно стабильно, поэтому применение к ним алгоритмов прогнозирования позволяет получить качественный прогноз. Товары группы Y продаются менее стабильно, возможно для них стоит строить модели не для каждого артикула, а для группы, это позволяет сгладить временной ряд и обеспечить работу алгоритма прогнозирования. Товары группы Z продаются хаотично, поэтому для них вообще не стоит строить прогностические модели, потребность в них нужно рассчитывать на основе простых формул, например, среднемесячных продаж.
По статистике около 70 % ассортимента составляют товары группы Z. Еще около 25 % - товары группы Y и только примерно 5 % - товары группы X. Таким образом, построение и применение сложных моделей актуально максимум для 30 % товаров. Поэтому применение описанного выше подхода позволит сократить время на анализ и прогнозирование в 5-10 раз.
Параллельная обработка
Еще одной эффективной стратегией обработки больших объемов данных является разбиение данных на сегменты и построение моделей для каждого сегмента по отдельности, с дальнейшим объединением результатов. Чаще всего в больших объемах данных можно выделить несколько отличающихся друг от друга подмножеств. Это могут быть, например, группы клиентов, товаров, которые ведут себя схожим образом и для которых целесообразно строить одну модель.
В этом случае вместо построения одной сложной модели для всех можно строить несколько простых для каждого сегмента. Подобный подход позволяет повысить скорость анализа и снизить требования к памяти благодаря обработке меньших объемов данных в один проход. Кроме того, в этом случае аналитическую обработку можно распараллелить, что тоже положительно сказывается на затраченном времени. К тому же модели для каждого сегмента могут строить различные аналитики.
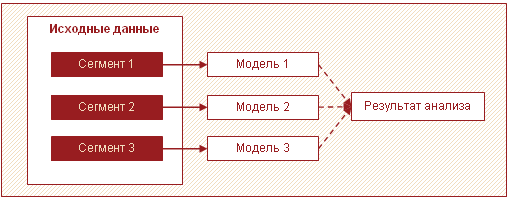
Помимо повышения скорости этот подход имеет и еще одно важное преимущество – несколько относительно простых моделей по отдельности легче создавать и поддерживать, чем одну большую. Можно запускать модели поэтапно, получая таким образом первые результаты в максимально сжатые сроки.
Репрезентативные выборки
При наличии больших объемов данных можно использовать для построения модели не всю информацию, а некоторое подмножество – репрезентативную выборку. Корректным образом подготовленная репрезентативная выборка содержит в себе информацию, необходимую для построения качественной модели.
Процесс аналитической обработки делится на 2 части: построение модели и применение построенной модели к новым данным. Построение сложной модели – ресурсоемкий процесс. В зависимости от применяемого алгоритма данные кэшируются, сканируются тысячи раз, рассчитывается множество вспомогательных параметров и т.п. Применение же уже построенной модели к новым данным требует ресурсов в десятки и сотни раз меньше. Очень часто это сводится к вычислению нескольких простых функций.
Таким образом, если модель будет строиться на относительно небольших множествах и применяться в дальнейшем ко всему набору данных, то время получения результата сократится на порядки по сравнению с попыткой полностью переработать весь имеющийся набор данных.

Для получения репрезентативных выборок существуют специальные методы, например, сэмплинг. Их применение позволяет повышать скорость аналитической обработки, не жертвуя качеством анализа.
Резюме
Описанные подходы – это только небольшая часть методов, которые позволяют анализировать огромные объемы данных. Существуют и другие способы, например, применение специальных масштабируемых алгоритмов, иерархических моделей, обучение окнами и прочее.
Анализ огромных баз данных – это нетривиальная задача, которая в большинстве случаев не решается "в лоб", однако современные базы данных и аналитические платформы предлагают множество методов решения этой задачи. При разумном их применении системы способны перерабатывать терабайты данных с приемлемой скоростью.
Термин «Биг-Дата», возможно, сегодня уже узнаваем, но вокруг него все еще довольно много путаницы относительно того, что же он означает на самом деле. По правде говоря, концепция постоянно развивается и пересматривается, поскольку она остается движущей силой многих продолжающихся волн цифрового преобразования, включая искусственный интеллект, науку о данных и Интернет вещей. Но что же представляет собой технология Big-Data и как она меняет наш мир? Давайте попробуем разобраться объяснить суть технологии Биг-Даты и что она означает простыми словами.
Все началось со «взрыва» в объеме данных, которые мы создали с самого начала цифровой эпохи. Это во многом связано с развитием компьютеров, Интернета и технологий, способных «выхватывать» данные из окружающего нас мира. Данные сами по себе не являются новым изобретением. Еще до эпохи компьютеров и баз данных мы использовали бумажные записи транзакций, клиентские записи и архивные файлы, которые и являются данными. Компьютеры, в особенности электронные таблицы и базы данных, позволили нам легко и просто хранить и упорядочивать данные в больших масштабах. Внезапно информация стала доступной при помощи одного щелчка мыши.
Тем не менее, мы прошли долгий путь от первоначальных таблиц и баз данных. Сегодня через каждые два дня мы создаем столько данных, сколько мы получили с самого начала вплоть до 2000 года. Правильно, через каждые два дня. И объем данных, которые мы создаем, продолжает стремительно расти; к 2020 году объем доступной цифровой информации возрастет примерно с 5 зеттабайтов до 20 зеттабайтов.
В настоящее время почти каждое действие, которое мы предпринимаем, оставляет свой след. Мы генерируем данные всякий раз, когда выходим в Интернет, когда переносим наши смартфоны, оборудованные поисковым модулем, когда разговариваем с нашими знакомыми через социальные сети или чаты и т.д. К тому же, количество данных, сгенерированных машинным способом, также быстро растет. Данные генерируются и распространяются, когда наши «умные» домашние устройства обмениваются данными друг с другом или со своими домашними серверами. Промышленное оборудование на заводах и фабриках все чаще оснащается датчиками, которые аккумулируют и передают данные.
Термин «Big-Data» относится к сбору всех этих данных и нашей способности использовать их в своих интересах в широком спектре областей, включая бизнес.
Как работает технология Big-Data?
Биг Дата работает по принципу: чем больше вы знаете о том или ином предмете или явлении, тем более достоверно вы сможете достичь нового понимания и предсказать, что произойдет в будущем. В ходе сравнения большего количества точек данных возникают взаимосвязи, которые ранее были скрыты, и эти взаимосвязи позволяют нам учиться и принимать более взвешенные решения. Чаще всего это делается с помощью процесса, который включает в себя построение моделей на основе данных, которые мы можем собрать, и дальнейший запуск имитации, в ходе которой каждый раз настраиваются значения точек данных и отслеживается то, как они влияют на наши результаты. Этот процесс автоматизирован — современные технологии аналитики будут запускать миллионы этих симуляций, настраивая все возможные переменные до тех пор, пока не найдут модель — или идею — которые помогут решить проблему, над которой они работают.
Бил Гейтс висит над бумажным содержимым одного компакт диска
До недавнего времени данные были ограничены электронными таблицами или базами данных — и все было очень упорядочено и аккуратно. Все то, что нельзя было легко организовать в строки и столбцы, расценивалось как слишком сложное для работы и игнорировалось. Однако прогресс в области хранения и аналитики означает, что мы можем фиксировать, хранить и обрабатывать большое количество данных различного типа. В результате «данные» на сегодняшний день могут означать что угодно, начиная базами данных, и заканчивая фотографиями, видео, звукозаписями, письменными текстами и данными датчиков.
Чтобы понять все эти беспорядочные данные, проекты, имеющие в основе Биг Дату, зачастую используют ультрасовременную аналитику с привлечением искусственного интеллекта и компьютерного обучения. Обучая вычислительные машины определять, что же представляют собой конкретные данные — например, посредством распознавания образов или обработки естественного языка – мы можем научить их определять модели гораздо быстрее и достовернее, чем мы сами.
Как используется Биг-Дата?
Этот постоянно увеличивающийся поток информации о данных датчиков, текстовых, голосовых, фото- и видеоданных означает, что теперь мы можем использовать данные теми способами, которые невозможно было представить еще несколько лет назад. Это привносит революционные изменения в мир бизнеса едва ли не в каждой отрасли. Сегодня компании могут с невероятной точностью предсказать, какие конкретные категории клиентов захотят сделать приобретение, и когда. Биг Дата также помогает компаниям выполнять свою деятельность намного эффективнее.
Даже вне сферы бизнеса проекты, связанные с Big-Data, уже помогают изменить наш мир различными путями:
- Улучшая здравоохранение — медицина, управляемая данными, способна анализировать огромное количество медицинской информации и изображений для моделей, которые могут помочь обнаружить заболевание на ранней стадии и разработать новые лекарства.
- Прогнозируя и реагируя на природные и техногенные катастрофы. Данные датчиков можно проанализировать, чтобы предсказать, где могут произойти землетрясения, а модели поведения человека дают подсказки, которые помогают организациям оказывать помощь выжившим. Технология Биг Даты также используется для отслеживания и защиты потока беженцев из зон военных действий по всему миру.
- Предотвращая преступность. Полицейские силы все чаще используют стратегии, основанные на данных, которые включают их собственную разведывательную информацию и информацию из открытого доступа для более эффективного использования ресурсов и принятия сдерживающих мер там, где это необходимо.
Лучшие книги о технологии Big-Data
- Все лгут. Поисковики, Big Data и Интернет знают о вас всё .
- BIG DATA. Вся технология в одной книге .
- Индустрия счастья. Как Big Data и новые технологии помогают добавить эмоцию в товары и услуги .
- Революция в аналитике. Как в эпоху Big Data улучшить ваш бизнес с помощью операционной аналитики .
Проблемы с Big-Data
Биг Дата дает нам беспрецедентные идеи и возможности, но также поднимает проблемы и вопросы, которые необходимо решить:
- Конфиденциальность данных – Big-Data, которую мы сегодня генерируем, содержит много информации о нашей личной жизни, на конфиденциальность которой мы имеем полное право. Все чаще и чаще нас просят найти баланс между количеством персональных данных, которые мы раскрываем, и удобством, которое предлагают приложения и услуги, основанные на использовании Биг Даты.
- Защита данных — даже если мы решаем, что нас устраивает то, что у кого-то есть наши данные для определенной цели, можем ли мы доверять ему сохранность и безопасность наших данных?
- Дискриминация данных — когда вся информация будет известна, станет ли приемлемой дискриминация людей на основе данных из их личной жизни? Мы уже используем оценки кредитоспособности, чтобы решить, кто может брать деньги, и страхование тоже в значительной степени зависит от данных. Нам стоит ожидать, что нас будут анализировать и оценивать более подробно, однако следует позаботиться о том, чтобы это не усложняло жизнь тех людей, которые располагают меньшими ресурсами и ограниченным доступом к информации.
Выполнение этих задач является важной составляющей Биг Даты, и их необходимо решать организациям, которые хотят использовать такие данные. Неспособность осуществить это может сделать бизнес уязвимым, причем не только с точки зрения его репутации, но также с юридической и финансовой стороны.
Глядя в будущее
Данные меняют наш мир и нашу жизнь небывалыми темпами. Если Big-Data способна на все это сегодня — просто представьте, на что она будет способна завтра. Объем доступных нам данных только увеличится, а технология аналитики станет еще более продвинутой.
Для бизнеса способность применять Биг Дату будет становиться все более решающей в ближайшие годы. Только те компании, которые рассматривают данные как стратегический актив, выживут и будут процветать. Те же, кто игнорирует эту революцию, рискуют остаться позади.
Что такое Big Data (дословно — большие данные )? Обратимся сначала к оксфордскому словарю:
Данные — величины, знаки или символы, которыми оперирует компьютер и которые могут храниться и передаваться в форме электрических сигналов, записываться на магнитные, оптические или механические носители.
Термин Big Data используется для описания большого и растущего экспоненциально со временем набора данных. Для обработки такого количества данных не обойтись без .
Преимущества, которые предоставляет Big Data:
- Сбор данных из разных источников.
- Улучшение бизнес-процессов через аналитику в реальном времени.
- Хранение огромного объема данных.
- Инсайты. Big Data более проницательна к скрытой информации при помощи структурированных и полуструктурированных данных.
- Большие данные помогают уменьшать риск и принимать умные решения благодаря подходящей риск-аналитике
Примеры Big Data
Нью-Йоркская Фондовая Биржа ежедневно генерирует 1 терабайт данных о торгах за прошедшую сессию.
Социальные медиа : статистика показывает, что в базы данных Facebook ежедневно загружается 500 терабайт новых данных, генерируются в основном из-за загрузок фото и видео на серверы социальной сети, обмена сообщениями, комментариями под постами и так далее.
Реактивный двигатель генерирует 10 терабайт данных каждые 30 минут во время полета. Так как ежедневно совершаются тысячи перелетов, то объем данных достигает петабайты.
Классификация Big Data
Формы больших данных:
- Структурированная
- Неструктурированная
- Полуструктурированная
Структурированная форма
Данные, которые могут храниться, быть доступными и обработанными в форме с фиксированным форматом называются структурированными. За продолжительное время компьютерные науки достигли больших успехов в совершенствовании техник для работы с этим типом данных (где формат известен заранее) и научились извлекать пользу. Однако уже сегодня наблюдаются проблемы, связанные с ростом объемов до размеров, измеряемых в диапазоне нескольких зеттабайтов.
1 зеттабайт соответствует миллиарду терабайт
Глядя на эти числа, нетрудно убедиться в правдивости термина Big Data и трудностях сопряженных с обработкой и хранением таких данных.
Данные, хранящиеся в реляционной базе — структурированы и имеют вид,например, таблицы сотрудников компании
Неструктурированная форма
Данные неизвестной структуры классифицируются как неструктурированные. В дополнении к большим размерам, такая форма характеризуется рядом сложностей для обработки и извлечении полезной информации. Типичный пример неструктурированных данных — гетерогенный источник, содержащий комбинацию простых текстовых файлов, картинок и видео. Сегодня организации имеют доступ к большому объему сырых или неструктурированных данных, но не знают как извлечь из них пользу.

Полуструктурированная форма
Эта категория содержит обе описанные выше, поэтому полуструктурированные данные обладают некоторой формой, но в действительности не определяются с помощью таблиц в реляционных базах. Пример этой категории — персональные данные, представленные в XML файле.
Характеристики Big Data
Рост Big Data со временем:

Синим цветом представлены структурированные данные (Enterprise data), которые сохраняются в реляционных базах. Другими цветами — неструктурированные данные из разных источников (IP-телефония, девайсы и сенсоры, социальные сети и веб-приложения).
В соответствии с Gartner, большие данные различаются по объему, скорости генерации, разнообразию и изменчивости. Рассмотрим эти характеристики подробнее.
- Объем . Сам по себе термин Big Data связан с большим размером. Размер данных — важнейший показатель при определении возможной извлекаемой ценности. Ежедневно 6 миллионов людей используют цифровые медиа, что по предварительным оценкам генерирует 2.5 квинтиллиона байт данных. Поэтому объем — первая для рассмотрения характеристика.
- Разнообразие — следующий аспект. Он ссылается на гетерогенные источники и природу данных, которые могут быть как структурированными, так и неструктурированными. Раньше электронные таблицы и базы данных были единственными источниками информации, рассматриваемыми в большинстве приложений. Сегодня же данные в форме электронных писем, фото, видео, PDF файлов, аудио тоже рассматриваются в аналитических приложениях. Такое разнообразие неструктурированных данных приводит к проблемам в хранении, добыче и анализе: 27% компаний не уверены, что работают с подходящими данными.
- Скорость генерации . То, насколько быстро данные накапливаются и обрабатываются для удовлетворения требований, определяет потенциал. Скорость определяет быстроту притока информации из источников — бизнес процессов, логов приложений, сайтов социальных сетей и медиа, сенсоров, мобильных устройств. Поток данных огромен и непрерывен во времени.
- Изменчивость описывает непостоянство данных в некоторые моменты времени, которое усложняет обработку и управление. Так, например, большая часть данных неструктурирована по своей природе.
Big Data аналитика: в чем польза больших данных
Продвижение товаров и услуг : доступ к данным из поисковиков и сайтов, таких как Facebook и Twitter, позволяет предприятиям точнее разрабатывать маркетинговые стратегии.
Улучшение сервиса для покупателей : традиционные системы обратной связи с покупателями заменяются на новые, в которых Big Data и обработка естественного языка применяется для чтения и оценки отзыва покупателя.
Расчет риска , связанного с выпуском нового продукта или услуги.
Операционная эффективность : большие данные структурируют, чтобы быстрее извлекать нужную информацию и оперативно выдавать точный результат. Такое объединение технологий Big Data и хранилищ помогает организациям оптимизировать работу с редко используемой информацией.
У каждой промышленной революции были свои символы: чугун и пар, сталь и поточное производство, полимеры и электроника, а очередная революция пройдет под знаком композитных материалов и данных. Big Data - ложный след или будущее индустрии?
20.12.2011 Леонид Черняк
Символами первой промышленной революции были чугун и пар, второй - сталь и поточное производство, третьей - полимерные материалы, алюминий и электроника, а очередная революция пройдет под знаком композитных материалов и данных. Big Data -это ложный след или будущее индустрии?
Уже более трех лет много говорят и пишут о Больших Данных (Big Data) в сочетании со словом «проблема», усиливая таинственность этой темы. За это время «проблема» оказалась в фокусе внимания подавляющего большинства крупных производителей, в расчете на обнаружение ее решения создается множество стартапов, а все ведущие отраслевые аналитики трубят о том, насколько сейчас важно умение работать с большими объемами данных для обеспечения конкурентоспособности. Подобная, не слишком аргументированная, массовость провоцирует инакомыслие, и можно встретить немало скептических высказываний на ту же тему, а иногда к Big Data даже прикладывают эпитет red herring (букв. «копченая селедка» - ложный след, отвлекающий маневр).
Так что же такое Big Data? Проще всего представить Big Data в виде стихийно обрушившейся и невесть откуда взявшейся лавины данных или свести проблему к новым технологиям, радикально изменяющим информационную среду, а может быть, вместе с Big Data мы переживаем очередной этап в технологической революции? Скорее всего, и то, и другое, и третье, и еще пока неведомое. Показательно, что из более чем четыре миллиона страниц в Web, содержащих словосочетание Big Data, один миллион содержит еще и слово definition - как минимум четверть пишущих о Big Data пытается дать свое определение. Такая массовая заинтересованность свидетельствует в пользу того, что, скорее всего, в Big Data есть что-то качественно иное, чем то, к чему подталкивает обыденное сознание.
Предыстория
То, что подавляющая часть упоминаний Big Data так или иначе связана с бизнесом, может ввести в заблуждение. На самом деле термин родился отнюдь не в корпоративной среде, а заимствован аналитиками из научных публикаций. Big Data относится к числу немногих названий, имеющих вполне достоверную дату своего рождения - 3 сентября 2008 года, когда вышел специальный номер старейшего британского научного журнала Nature, посвященный поиску ответа на вопрос «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объемами данных?». Специальный номер подытоживает предшествующие дискуссии о роли данных в науке вообще и в электронной науке (e-science) в частности.
Роль данных в науке стала предметом обсуждения очень давно - первым об обработке данных еще в XVIII веке писал английский астроном Томас Симпсон в труде «О преимуществах использования чисел в астрономических наблюдениях», но только в конце прошлого столетия интерес к этой теме приобрел заметную остроту, а на передний план обработка данных вышла в конце прошлого века, когда обнаружилось, что компьютерные методы могут применяться практически во всех науках от археологии до ядерной физики. Как следствие, заметно меняются и сами научные методы. Не случайно появился неологизм libratory, образованный от слов library (библиотека) и laboratory (лаборатория), который отражает изменения, касающиеся представления о том, что можно считать результатом исследования. До сих пор на суд коллег представлялись только полученные конечные результаты, а не сырые экспериментальные данные, а теперь, когда в «цифру» могут быть переведены самые разные данные, когда имеются разнообразные цифровые носители, то объектом публикации могут быть различного рода измеренные данные, причем особое значение приобретает возможность повторной обработки в libratory ранее накопленных данных. А далее складывается положительная обратная связь, за счет которой процесс накопления научных данных постоянно ускоряется. Именно поэтому, осознавая масштаб грядущих изменений, редактор номера Nature Клиффорд Линч предложил для новой парадигмы специальное название Большие Данные, выбранное им по аналогии с такими метафорами, как Большая Рефть, Большая Руда и т. п., отражающими не столько количество чего-то, сколько переход количества в качество.
Большие Данные и бизнес
Не прошло и года, как термин Big Data попал на страницы ведущих бизнес-изданий, в которых, однако, использовались уже совсем иные метафоры. Big Data сравнивают с минеральными ресурсами - the new oil (новая нефть), goldrush (золотая лихорадка), data mining (разработка данных), чем подчеркивается роль данных как источника скрытой информации; с природными катаклизмами - data tornado (ураган данных), data deluge (наводнение данных), data tidal wave (половодье данных), видя в них угрозу; улавливая связь с промышленным производством - data exhaust (выброс данных), firehose (шланг данных), Industrial Revolution (промышленная революция). В бизнесе, как и в науке, большие объемы данных тоже не есть что-то совершенно новое - уже давно говорили о необходимости работы с большими объемами данных, например в связи с распространением радиочастотной идентификации (RFID) и социальных сетей, и так же, как и в науке, здесь не хватало только яркой метафоры для определения происходящего. Вот почему в 2010 году появились первые продукты, претендующие на попадание в категорию Big Data, - нашлось подходящее название для уже существующих вещей. Показательно, что в версию 2011 Hype Cycle, характеризующую состояние и перспективы новых технологий, аналитики Gartner ввели еще одну позицию Big Data and Extreme Information Processing and Management с оценкой срока массового внедрения соответствующих решений от двух до пяти лет.
Почему Большие Данные оказались проблемой?
С момента появления термина Big Data прошло уже три года, но если в науке все более или менее ясно, то место Big Data в бизнесе остается неопределенным, не случайно так часто говорят о «проблеме Больших Данных», причем не просто о проблеме, но ко всему прочему еще и плохо определенной. Нередко проблему упрощают, интерпретируя наподобие закона Мура, с той лишь разницей, что в данном случае мы имеем дело с феноменом удвоения количества данных за год, или гиперболизируют, представляя чуть ли не как стихийное бедствие, с которым срочно нужно каким-то способом справиться. Данных действительно становится все больше и больше, но при всем этом упускается из виду то обстоятельство, что проблема отнюдь не внешняя, она вызвана не столько обрушившимися в невероятном количестве данными, сколько неспособностью старыми методами справиться с новыми объемами, и, что самое главное, нами самими создаваемыми. Наблюдается странный дисбаланс - способность порождать данные оказалась сильнее, чем способность их перерабатывать. Причина возникновения этого перекоса заключается, скорее всего, в том, что за 65 лет истории компьютеров мы так и не поняли, что же такое данные и как они связаны с результатами обработки. Странно, математики столетиями разбираются с основными понятиями своей науки, такими как число и системы счисления, привлекая к этому философов, а в нашем случае данные и информация, отнюдь не тривиальные вещи, оставлены без внимания и отданы на откуп интуитивному восприятию. Вот и получилось, что все эти 65 лет невероятными темпами развивались собственно технологии работы с данными и почти не развивалась кибернетика и теория информации, оставшиеся на уровне 50-х годов, когда ламповые компьютеры использовались исключительно для расчетов. Действительно, наблюдаемая сейчас суета вокруг Big Data при внимательном вызывает скептическую улыбку.
Масштабирование и многоуровневое хранение
Облака, большие данные, аналитика – эти три фактора современных ИТ не только взаимосвязаны, но сегодня уже не могут существовать друг без друга. Работа с Большими Данными невозможна без облачных хранилищ и облачных вычислений – появление облачных технологий не только в виде идеи, а уже в виде законченных и реализованных проектов стало спусковым крючком для запуска нового витка спирали увеличения интереса к аналитике Больших Данных. Если говорить о влиянии на индустрию в целом, то сегодня стали очевидны возросшие требования к масштабированию систем хранения. Это действительно необходимое условие – ведь заранее сложно предсказать, для каких аналитических процессов понадобятся те или иные данные и насколько интенсивно будет загружено существующее хранилище. Кроме этого, становятся одинаково важны требования как по вертикальному, так и горизонтальному масштабированию.
В новом поколении своих систем хранения компания Fujitsu уделила большое внимание именно аспектам масштабирования и многоуровнего хранения данных. Практика показывает, что сегодня для выполнения аналитических задач требуется сильно загружать системы, однако бизнес требует, чтобы все сервисы, приложения и сами данные всегда оставались доступными. Кроме этого, требования к результатам аналитических исследований сегодня очень высоки – грамотно, правильно и своевременно проведенные аналитические процессы позволяют существенно улучшить результаты работы бизнеса в целом.
– Александр Яковлев ([email protected]), менеджер по маркетингу продукции Fujitsu (Москва).
Игнорированием роли данных и информации, как предметов исследования, была заложена та самая мина, которая взорвалась сейчас, в момент, когда изменились потребности, когда счетная нагрузка на компьютеры оказалась намного меньше, чем другие виды работ, выполняемые над данными, а цель этих действий заключается в получении новой информации и новых знаний из уже существующих массивов данных. Вот почему вне восстановления связей цепочки «данные - информация - знание» говорить о решении проблемы Больших Данных бессмысленно. Данные обрабатываются для получения информации, которой должно быть ровно столько, чтобы человек мог превратить ее в знание.
За последние десятилетия серьезных работ по связям сырых данных с полезной информацией не было, а то, что мы привычно называем теорией информации Клода Шеннона, является не чем иным, как статистической теорией передачи сигналов, и к информации, воспринимаемой человеком, не имеет никакого отношения. Есть множество отдельных публикаций, отражающих частные точки зрения, но нет полноценной современной теории информации. В результате подавляющее число специалистов вообще не делает различия между данными и информацией. Вокруг все только констатируют, что данных много или очень много, но зрелого представления, чего именно много, какими путями следует решать возникшую проблему, нет ни у кого - а все потому, что технические возможности работы с данными явно опередили уровень развития способностей к их использованию. Только у одного автора, редактора журнала Web 2.0 Journal Дайона Хинчклифа, имеется классификация Больших Данных, позволяющая соотнести технологии с результатом, который ждут от обработки Больших Данных, но и она далеко не удовлетворительна.
Хинчклиф делит подходы к Big Data на три группы: Быстрые Данные (Fast Data), их объем измеряется терабайтами; Большая Аналитика (Big Analytics) - петабайтные данные и Глубокое Проникновение (Deep Insight) - экзабайты, зеттабайты. Группы различаются между собой не только оперируемыми объемами данных, но и качеством решения по их обработки.
Обработка для Fast Data не предполагает получения новых знаний, ее результаты соотносятся с априорными знаниями и позволяют судить о том, как протекают те или иные процессы, она позволяет лучше и детальнее увидеть происходящее, подтвердить или отвергнуть какие-то гипотезы. Только небольшая часть из существующих сейчас технологий подходит для решения задач Fast Data, в этот список попадают некоторые технологии работы с хранилищами (продукты Greenplum, Netezza, Oracle Exadata, Teradata, СУБД типа Verica и kdb). Скорость работы этих технологий должна возрастать синхронно с ростом объемов данных.
Задачи, решаемые средствами Big Analytics, заметно отличаются, причем не только количественно, но и качественно, а соответствующие технологии должны помогать в получении новых знаний - они служат для преобразования зафиксированной в данных информации в новое знание. Однако на этом среднем уровне не предполагается наличие искусственного интеллекта при выборе решений или каких-либо автономных действий аналитической системы - она строится по принципу «обучения с учителем». Иначе говоря, весь ее аналитический потенциал закладывается в нее в процессе обучения. Самый очевидный пример - машина , играющая в Jeopardy!. Классическими представителями такой аналитики являются продукты MATLAB, SAS, Revolution R, Apache Hive, SciPy Apache и Mahout.
Высший уровень, Deep Insight, предполагает обучение без учителя (unsupervised learning) и использование современных методов аналитики, а также различные способы визуализации. На этом уровне возможно обнаружение знаний и закономерностей, априорно неизвестных.
Аналитика Больших Данных
С течением времени компьютерные приложения становятся все ближе к реальному миру во всем его многообразии, отсюда рост объемов входных данных и отсюда же потребность в их аналитике, причем в режиме, максимально приближенном к реальному времени. Конвергенция этих двух тенденций привела к возникновению направления аналитика Больших Данных (Big Data Analytics).
Победа компьютера Watson стала блестящей демонстрацией возможностей Big Data Analytics - мы вступаем в интереснейшую эпоху, когда компьютер впервые используется не столько как инструмент для ускорения расчетов, а как помощник, расширяющий человеческие возможности в выборе информации и принятии решений. Казавшиеся утопическими замыслы Ванневара Буша, Джозефа Ликлайдера и Дага Энгельбарта начинают сбываться, но происходит это не совсем так, как это виделось десятки лет назад - сила компьютера не в превосходстве над человеком по логическим возможностям, на что особенно уповали ученые, а в существенно большей способности обрабатывать гигантские объемы данных. Нечто подобное было в противоборстве Гарри Каспарова с Deep Blue, компьютер не был более искусным игроком, но он мог быстрее перебирать большее количество вариантов.
Гигантские объемы в сочетании с высокой скоростью, отличающие Big Data Analytics от других приложений, требуют соответствующих компьютеров, и сегодня практически все основные производители предлагают специализированные программно-аппаратные системы: SAP HANA, Oracle Big Data Appliance, Oracle Exadata Database Machine и Oracle Exalytics Business Intelligence Machine, Teradata Extreme Performance Appliance, NetApp E-Series Storage Technology, IBM Netezza Data Appliance, EMC Greenplum, Vertica Analytics Platform на базе HP Converged Infrastructure. Помимо этого в игру вступило множество небольших и начинающих компаний: Cloudera, DataStax, Northscale, Splunk, Palantir, Factual, Kognitio, Datameer, TellApart, Paraccel, Hortonworks.
Обратная связь
Качественно новые приложения Big Data Analytics требуют для себя не только новых технологий, но и качественного иного уровня системного мышления, а вот с этим наблюдаются трудности - разработчики решений Big Data Analytics часто заново открывают истины, известные с 50-х годов. В итоге нередко аналитика рассматривается в отрыве от средств подготовки исходных данных, визуализации и других технологий предоставления результатов человеку. Даже такая уважаемая организация, как The Data Warehousing Institute, рассматривает аналитику в отрыве от всего остального: по ее данным, уже сейчас 38% предприятий исследуют возможность использования Advanced Analytics в практике управления, а еще 50% намереваются сделать это в течение ближайших трех лет. Такой интерес обосновывается приведением множества аргументов из бизнеса, хотя можно сказать и проще - предприятиям в новых условиях требуется более совершенная система управления, и начинать ее создание надо с установления обратной связи, то есть с системы, помогающей в принятии решений, а в будущем, может быть, удастся автоматизировать и собственно приятие решений. Удивительно, но все сказанное укладывается в методику создания автоматизированных систем управления технологическими объектами, известную с 60-х годов.
Новые средства для анализа требуются потому, что данных становится не просто больше, чем раньше, а больше их внешних и внутренних источников, теперь они сложнее и разнообразнее (структурированные, неструктурированные и квазиструктурированные), используются различные схемы индексации (реляционные, многомерные, noSQL). Прежними способами справиться с данными уже невозможно - Big Data Analytics распространяется на большие и сложные массивы, поэтому еще используют термины Discovery Analytics (открывающая аналитика) и Exploratory Analytics (объясняющая аналитика). Как ни называть, суть одна - обратная связь, снабжающая в приемлемом виде лиц, принимающих решение, сведениями о различного рода процессах.
Компоненты
Для сбора сырых данных используются соответствующие аппаратные и программные технологии, какие именно - зависит от природы объекта управления (RFID, сведения из социальных сетей, разнообразные текстовые документы и т. п.). Эти данные поступают на вход аналитической машины (регулятора в цепи обратной связи, если продолжать аналогию с кибернетикой). Этот регулятор базируется на программно-аппаратной платформе, на которой работает собственно аналитическое ПО, он не обеспечивает выработки управляющих воздействий, достаточных для автоматического управления, поэтому в контур включаются ученые по данным (data scientist) или инженеры в области данных. Их функцию можно сравнить с той ролью, которую играют, например, специалисты в области электротехники, использующие знания из физики в приложении к созданию электрических машин. Задача инженеров заключается в управлении процессом преобразования данных в информацию, используемую для принятия решений, - они-то и замыкают цепочку обратной связи. Из четырех компонентов Big Data Analytics в данном случае нас интересует только один - программно-аппаратная платформа (системы этого типа называют Analytic Appliance или Data Warehouse Appliance).
На протяжении ряда лет единственным производителем аналитических специализированных машин была Teradata, но не она была первой - еще в конце 70-х годов тогдашний лидер британской компьютерной индустрии компания ICL предприняла не слишком удачную попытку создать контентно-адресуемое хранилище (Content-Addressable Data Store), в основе которого была СУБД IDMS. Но первой создать «машину баз данных» удалось компании Britton-Lee в 1983 году на базе мультипроцессорной конфигурации процессоров семейства Zilog Z80. В последующем Britton-Lee была куплена Teradata, с 1984 года выпускавшая компьютеры MPP-архитектуры для систем поддержки принятия решений и хранилищ данных. А первым представителем нового поколения поставщиков подобных комплексов стала компания Netezza - в ее решении Netezza Performance Server использовались стандартные серверы-лезвия вместе со специализированными лезвиями Snippet Processing Unit.
Аналитика в СУБД
Аналитика здесь - прежде всего прогнозная , или предиктивная (Predictive Analysis, РА). В большинстве существующих реализаций исходными для систем РА являются данные, ранее накопленные в хранилищах данных. Для анализа данные сначала перемещают в промежуточные витрины (Independent Data Mart, IDM), где представление данных не зависит от использующих их приложений, а затем те же данные переносятся в специализированные аналитические витрины (Аnalytical Data Mart, ADM), и уже с ними работают специалисты, применяя различные инструменты разработки, или добычи данных (Data Mining). Такая многоступенчатая модель вполне приемлема для относительно небольших объемов данных, но при их увеличении и при повышении требований к оперативности в такого рода моделях обнаруживается ряд недостатков. Помимо необходимости в перемещении данных существование множества независимых ADM приводит к усложнению физической и логической инфраструктуры, разрастается количеств используемых инструментов моделирования, полученные разными аналитиками результаты оказываются несогласованны, далеко не оптимально используются вычислительные мощности и каналы. Кроме того, раздельное существование хранилищ и ADM делает практически невозможной аналитику во времени, приближенном к реальному.
Выходом может быть подход, получивший название In-Database Analytics или No-Copy Analytics, предполагающий использование для целей аналитики данных, непосредственно находящихся в базе. Такие СУБД иногда называют аналитическими и параллельными. Подход стал особенно привлекателен с появлением технологий MapReduce и Hadoop. В новых приложениях поколения класса In-Database Analytics все виды разработки данных и другие виды интенсивной работы выполняются непосредственно над данными, находящимися в хранилище. Очевидно, что это заметно ускоряет процессы и позволяет выполнять в реальном времени такие приложения, как распознавание образов, кластеризация, регрессионный анализ, различного рода прогнозирование. Ускорение достигается не только за счет избавления от перемещений из хранилища в витрины, но главным образом за счет использования различных методов распараллеливания, в том числе кластерных систем с неограниченным масштабированием. Решения типа In-Database Analytics открывают возможность для использования облачных технологий в приложении к аналитике. Следующим шагом может стать технология SAP HANA (High Performance Analytic Appliance), суть которой в размещении данных для анализа в оперативной памяти.
Основные поставщики...
К 2010 году основными поставщиками ПО для In-Database Analytics были компании Aster Data (Aster nCluster), Greenplum (Greenplum Database), IBM (InfoSphere Warehouse; IBM DB2), Microsoft (SQL Server 2008), Netezza (Netezza Performance System, PostGresSQL), Oracle (Oracle Database 11g/10g, Oracle Exadata), SenSage (SenSage/columnar), Sybase (Sybase IQ), Teradata и Vertica Systems (Vertica Analytic Database). Все это хорошо известные компании, за исключением стартапа из Кремниевой долины SenSage. Продукты заметно различаются по типу данных, с которыми они могут работать, по функциональным возможностям, интерфейсам, по применяемому аналитическому ПО и по их способности работать в облаках. Лидером по зрелости решений является Teradata, а по авангардности - Aster Data. Список поставщиков аналитического ПО короче - в локальных конфигурациях могут работать продукты компаний KXEN, SAS, SPSS и TIBCO, а в облаках - Amazon, Cascading, Google, Yahoo! и Сloudera.
Год 2010-й стал поворотным в области предиктивной аналитики, сравнимым с 2007 годом, когда IBM приобрела Cognos, SAP - Business Object, а Oracle - Hyperion. Все началось с того, что EMC приобрела Greenplum, затем IBM - Netezza, HP - Vertica, Teradata купила Aster Data и SAP купила Sybase.
…и новые возможности
Аналитическая парадигма открывает принципиально новые возможности, что успешно доказали два инженера из Кёльна, создавшие компанию ParStream (официальное имя empulse GmbH). Вдвоем им удалось создать аналитическую платформу на базе процессоров как универсальных, так и графических процессоров, конкурентную с предшественниками. Четыре года назад Михаэль Хюммепль и Джорг Бинерт, работавшие прежде в Accenture, получили заказ от германской туристической фирмы, которой для формирования туров требовалась система, способная за 100 миллисекунд выбирать запись, содержащую 20 параметров, в базе из 6 млрд записей. Ни одно из существующих решений с такой задачей справиться не может, хотя с аналогичными проблемами сталкиваются везде, где требуется оперативный анализ содержимого очень больших баз данных. Компания ParStream родилась из предпосылки применения технологий высокопроизводительных вычислений к Big Data Analytics. Хюммепль и Бинерт начали с того, что написали собственное ядро СУБД, рассчитанное для работы на кластере x86-архитектуры, поддерживающем операции с данными в виде параллельных потоков, отсюда и название ParStream. Они избрали в качестве исходной установки работу только со структурированными данными, что собственно и открывает возможность для относительно простого распараллеливания. По своему замыслу эта база данных ближе к новому проекту Google Dremel, чем к MapReduce или Hadoop, которые не адаптированы к запросам в реальном времени. Начав с платформы x86/Linux, Хюммепль и Бинерт вскоре убедились, что их база данных может поддерживаться и графические процессоры nVidia Fermi.
Big Data и Data Processing
Чтобы понять, чего же следует ожидать от того, что назвали Big Data, следует выйти за границы современного узкого «айтишного» мировоззрения и попытаться увидеть происходящее в более широкой историко-технологической ретроспективе, например попробовать найти аналогии с технологиями, имеющими более длительную историю. Ведь, назвав предмет нашей деятельности технологией, надо и относиться к нему как к технологии. Практически все известные материальные технологии сводятся к переработке, обработке или сборке специфического для них исходного сырья или каких-то иных компонентов с целью получения качественно новых продуктов - что-то имеется на входе технологического процесса и нечто на выходе.
Особенность нематериальных информационных технологий состоит в том, что здесь не столь очевидна технологическая цепочка, не ясно, что является сырьем, что результатом, что поступает на вход и что получается на выходе. Проще всего сказать, что на входе сырые данные, а на выходе полезная информация. В целом почти верно, однако связь между этими двумя сущностями чрезвычайно сложна; если же остаться на уровне здоровой прагматики, то можно ограничиться следующими соображениями. Данные - это выраженные в разной форме сырые факты, которые сами по себе не несут полезного смысла до тех пор, пока не поставлены в контекст, должным образом не организованы и не упорядочены в процессе обработки. Информация появляется в результате анализа обработанных данных человеком, этот анализ придает данным смысл и обеспечивает им потребительские качеств. Данные - это неорганизованные факты, которые необходимо превращать в информацию. До последнего времени представления об обработке данных (data processing) сводились к органичному кругу алгоритмических, логических или статистических операций над относительно небольшими объемами данных. Однако по мере сближения компьютерных технологий с реальным миром возрастает потребность превращений данных из реального мира в информацию о реальном мире, обрабатываемых данных становится больше, и требования к скорости обработки возрастают.
Логически информационные технологии мало чем отличаются от материальных технологий, на входе сырые данные, на выходе - структурированные, в форме, более удобной для восприятия человеком, извлечения из них информации и силой интеллекта превращения информации в полезное знание. Компьютеры назвали компьютерами за их способность считать, вспомним первое приложение для ENIAC - обработка данных стрельбы из орудия и превращение их в артиллерийские таблицы. То есть компьютер перерабатывал сырые данные, извлекал полезные и записывал их в форме, приемлемой для использования. Перед нами не что иное, как обычный технологический процесс. Вообще говоря, вместо привившегося термина Information Technology следовало бы чаще употреблять более точный Data Processing.
На информационные технологии должны распространяться общие закономерности, в согласии с которыми развиваются все остальные технологии, а это прежде всего увеличение количества перерабатываемого сырья и повышение качества переработки. Так происходит везде, независимо от того, что именно служит сырьем, а что результатом, будь то металлургия, нефтехимия, биотехнологии, полупроводниковые технологии и т. д. Общим является еще и то, что ни одно из технологических направлений не развивается монотонно, рано или поздно возникают моменты ускоренного развития, скачки. Быстрые переходы могут происходить в тех случаях, когда вовне возникает потребность, а внутри технологий есть способность ее удовлетворить. Компьютеры нельзя было строить на вакуумных лампах - и появились полупроводники, автомобилям нужно много бензина - открыли крекинг-процесс, и таких примеров множество. Таким образом, под именем Big Data скрывается намечающийся качественный переход в компьютерных технологиях, способный повлечь за собой серьезные изменения, не случайно его называют новой промышленной революцией. Big Data - очередная техническая революция со всеми вытекающими последствиями.
Первый опыт в Data Processing датируется IV тысячелетием до нашей эры, когда появилось пиктографическое письмо. С тех пор сложилось несколько основных направлений работы с данными, самым мощным было и остается текстовое, от первых глиняных табличек до SSD, от библиотек середины первого тысячелетия до нашей эры до современных библиотек, затем появились различного рода математические численные методы от папирусов с доказательством теоремы Пифагора и табличных приемов упрощения расчетов до современных компьютеров. По мере развития общества стали копиться различного рода табличные данные, автоматизация работы с которыми началась с табуляторов, а в XIX и ХХ веке было предложено множество новых методов создания и накопления данных. Необходимость работы с большими объемами данных понимали давно, но не было средств, отсюда утопические проекты типа «Либрариума» Поля Отле, или фантастическая система для прогнозирования погоды с использованием труда 60 тыс. людей-расчетчиков.
Сегодня компьютер превратился в универсальный инструмент для работы с данными, хотя задумывался он только лишь для автоматизации расчетов. Идея применить компьютер для Data Processing зародилась в IBM через десять лет после изобретения цифровых программируемых компьютеров, а до этого для обработки данных использовались перфораторные устройства типа Unit Record, изобретенные Германом Холлеритом. Их называли Unit Record, то есть единичная запись - каждая карта содержала всю запись, относящуюся к какому-то одному объекту. Первые компьютеры не умели работать с Большими Данными - лишь с появлением накопителей на дисках и лентах они смогли составить конкуренцию машино-счетным станциям, просуществовавшим до конца 60-х годов. Кстати, в реляционных базах данных явным образом прослеживается наследие Unit Record.
Простота – залог успеха
Рост объемов сырых данных вместе с необходимостью их анализа в режиме реального времени требуют создания и внедрения инструментов, позволяющих эффективно решать так называемую задачу Big Data Analytics. Технологии компании Information Builders позволяют работать с данными, поступающими из любых источников в режиме реального времени, благодаря множеству различных адаптеров и архитектуре Enterprise Service Bus. Инструмент WebFOCUS позволяет анализировать данные «на лету» и дает возможность визуализировать результаты лучшим для пользователя способом.
Основываясь на технологии RSTAT, компания Information Builders создала продукт для предиктивной аналитики, позволяющий проводить сценарное прогнозирование: «Что будет, если» и «Что необходимо для».
Технологии бизнес-аналитики пришли и в Россию, однако лишь немногие российские компании используют именно предиктивный анализ, что вызвано низкой культурой использования бизнес-аналитики на отечественных предприятиях и сложностью восприятия существующих методов анализа бизнес-пользователем. Учитывая это, компания Information Builders предлагает сегодня продукты, которые аналитиками Gartner оцениваются как самые простые в использовании.
– Михаил Строев ([email protected]), директор по развитию бизнеса в России и СНГ InfoBuild CIS (Москва).
Данные повсюду
По мере постепенного превращения компьютеров из счетных устройств в универсальные машины для обработки данных, примерно после 1970 года, стали появляться новые термины: данные как продукты (data product); инструменты для работы с данными (data tool); приложения, реализуемые посредством соответствующей организации (data application); наука о данных (data science); ученые, работающие с данными (data scientist), и даже журналисты, которые доносят сведения, содержащиеся в данных, до широкой публики (data journalist).
Большое распространение сегодня получили приложения класса data application, которые не просто выполняют операции над данными, а извлекают из них дополнительные ценности и создают продукты в виде данных. К числу первых приложений этого типа относится база аудиодисков CDDB, которая в отличие от традиционных баз данных создана путем экстрагирования данных из дисков и сочетания их с метаданными (названия дисков, треков и т. п.). Эта база лежит в основе сервиса Apple iTunes. Одним из факторов коммерческого успеха Google также стало осознание роли data application - владение данными позволяет этой компании многое «знать», используя данные, лежащие вне искомой страницы (алгоритм PageRank). В Google достаточно просто решена проблема корректности правописания - для этого создана база данных ошибок и исправлений, а пользователю предлагаются исправления, которые он может принять или отклонить. Аналогичный подход применяется и для распознавания при речевом вводе - в его основе накопленные аудиоданные.
В 2009 году во время вспышки свиного гриппа анализ запросов к поисковым машинам позволил проследить процесс распространения эпидемии. По пути Google пошли многие компании (Facebook, LinkedIn, Amazon и др.), не только предоставляющие услуги, но и использующие накопленные данные в иных целях. Возможность обрабатывать данные такого типа дала толчок к появлению еще одной науки о населении - citizen science. Результаты, полученные путем всестороннего анализа данных о населении, позволяют получить гораздо более глубокие знания о людях и принимать более обоснованные административные и коммерческие решения. Совокупность данных и средств работы с ними сейчас называют infoware.
Машина для Больших Данных
Хранилища данных, интернет-магазины, биллинговые системы или любая другая платформа, которую можно отнести к проектам Больших Данных, обычно обладает уникальной спецификой, и при ее проектировании главным является интеграция с промышленными данными, обеспечение процессов накопления данных, их организации и аналитики.
Компания Oracle предоставила интегрированное решение Oracle Big Data Appliance поддержки цепочки обработки Больших Данных, состоящее из оптимизированного оборудования с полным стеком программного обеспечения и 18 серверов Sun X4270 M2. Межсоединение строится на базе Infiniband 40 Гбит/с и 10-Gigabit Ethernet. Oracle Big Data Appliance включает в себя комбинацию как открытого, так и специализированного ПО от Oracle.
Хранилища типа ключ-значение или NoSQL СУБД признаны сегодня основными для мира Больших Данных и оптимизированы для быстрого накопления данных и доступа к ним. В качестве такой СУБД для Oracle Big Data Appliance используется СУБД на базе Oracle Berkley DB, хранящая информацию о топологии системы хранения, распределяющая данные и понимающая, где могут быть размещены данные с наименьшими временными затратами.
Решение Oracle Loader for Hadoop позволяет с помощью технологии MapReduce создавать оптимизированные наборы данных для их загрузки и анализа в СУБД Oracle 11g. Данные генерируются в «родном» формате СУБД Oracle, что позволяет минимизировать использование системных ресурсов. Обработка отформатированных данных осуществляется на кластере, а затем данные могут быть доступны с рабочих мест пользователей традиционной РСУБД с помощью стандартных команд SQL или средств бизнес-аналитики. Интеграция данных Hadoop и Oracle СУБД осуществляется при помощи решения Oracle Data Integrator.
Oracle Big Data Appliance поставляется с открытым дистрибутивом Apache Hadoop, включая файловую систему HDFS и другие компоненты, открытым дистрибутивом статистического пакета R для анализа сырых данных и системой Oracle Enterprise Linux 5.6. Предприятия, уже использующие Hadoop, могут интегрировать данные, размещенные на HDFS в СУБД Oracle с помощью функционала внешних таблиц, причем нет необходимости сразу загружать данные в СУБД – внешние данные могут быть использованы в связке с внутренними данными базы Oracle при помощи команд SQL.
Подключение между Oracle Big Data Appliance и Oracle Exadata через Infiniband обеспечивает высокоскоростную передачу данных для пакетной обработки или SQL-запросов. Oracle Exadata обеспечивает необходимую производительность как для хранилищ данных, так и для приложений оперативной обработки транзакций.
Новый продукт Oracle Exalytics может быть использован для решения задач бизнес аналитики и оптимизирован для использования Oracle Business Intelligence Enterprise Edition с обработкой в оперативной памяти.
– Владимир Демкин ([email protected]), ведущий консультант по направлению Oracle Exadata компании Oracle СНГ (Москва).
Наука и специалисты
Автор доклада «Что такое наука о данных?» (What is Data Science?), вышедшего в серии O’Reilly Radar Report, Майк Лукидис написал: «Будущее принадлежит компаниям и людям, способным превратить данные в продукты». Это высказывание невольно вызывает в памяти известные слова Ротшильда «Кто владеет информацией – тот владеет миром», произнесенные им, когда он раньше других узнал о поражении Наполеона при Ватерлоо и провернул аферу с ценными бумагами. Сегодня этот афоризм стоит перефразировать: «Миром владеет тот, кто владеет данными и технологиями их анализа». Живший немного позже Карл Маркс показал, что промышленная революция разделила людей на две группы - на владеющих средствами производства и тех, кто работает на них. В общих чертах сейчас происходит нечто подобное, но теперь предметом владения и разделения функций являются не средства производства материальных ценностей, а средства производства данных и информации. И вот тут-то и возникают проблемы - оказывается, владеть данными намного сложнее, чем владеть материальными активами, первые довольно просто тиражируются и вероятность их хищения гораздо выше, чем кражи материальных предметов. Кроме того, существуют легальные приемы разведки - при наличии достаточного объема и соответствующих аналитических методов можно «вычислить» то, что скрыто. Вот почему сейчас такое внимание уделяется аналитике Больших Данных Big Data Analytics (см. врезку) и средствам защиты от нее.
Различные виды деятельности с данными, и прежде всего владение методами извлечения информации, называют наукой о данных (data science), что, во всяком случае в переводе на русский, несколько дезориентирует, поскольку скорее относится не к некоторой новой академической науке, а к междисциплинарному набору знаний и навыков, необходимых для извлечения знаний. Состав подобного набора в значительной мере зависит от области, но можно выделить более или менее обобщенные квалификационные требования к специалистам, которых называют data scientist. Лучше всего это удалось сделать Дрю Конвей, который в прошлом занимался анализом данных о террористических угрозах в одной из спецслужб США. Основные тезисы его диссертации опубликованы в ежеквартальном журнале IQT Quarterly, который издавается компанией In-Q-Tel, выполняющей посредническую функцию между ЦРУ США и научными организациями.
Свою модель Конвей изобразил в виде диаграммы Венна (см. рисунок), представляющей три области знания и умений, которыми нужно владеть и обладать, чтобы стать специалистом по данным. Хакерские навыки не следует понимать как злоумышленные действия, в данном случае так названо сочетание владения определенным инструментарием с особым аналитическим складом ума, как у Эркюля Пуаро, или, возможно, эту способность можно назвать дедуктивным методом Шерлока Холмса. В отличие от великих сыщиков нужно еще быть экспертом в ряде математических направлений и понимать предмет. Машинное обучение образуется на пересечении первых двух областей, на пересечении второй и третьей - традиционные методы. Третья зона пересечения опасна спекулятивностью, без математических методов не может быть объективного видения. На пересечении всех трех зон лежит наука о данных.
Диаграмма Конвея дает упрощенную картину; во-первых, на пересечении хакерского и математического кругов лежит не только машинное обучение, во-вторых, размер последнего круга намного больше, сегодня он включает множество дисциплин и технологий. Машинным обучением называют только одну из областей искусственного интеллекта, связанную с построением алгоритмов, способных к обучению, она делится на две подобласти: прецедентное, или индуктивное обучение, выявляющее скрытые закономерности в данных, и дедуктивное, нацеленное на формализацию экспертных знаний. Еще машинное обучение делится на обучение с учителем (Supervised Learning), когда изучаются методы классификации, основанные на заранее подготовленных тренировочных наборах данных, и без учителя (Unsupervised Learning), когда внутренние закономерности ищутся посредством кластерного анализа.
Итак, Big Data - это не спекулятивные размышления, а символ настигающей технической революции. Необходимость в аналитической работе с большими данными заметно изменит лицо ИТ-индустрии и стимулирует появление новых программных и аппаратных платформ. Уже сегодня для анализа больших объемов данных применяются самые передовые методы: искусственные нейронные сети - модели, построенные по принципу организации и функционирования биологических нейронных сетей; методы предиктивной аналитики, статистики и Natural Language Processing (направления искусственного интеллекта и математической лингвистики, изучающего проблемы компьютерного анализа и синтеза естественных языков). Используются также и методы, привлекающие людей-экспертов, или краудсорсинг, А/В тестирование, сентимент-анализ и др. Для визуализации результатов применяются известные методы, например облака тегов и совсем новые Clustergram, History Flow и Spatial Information Flow.
Со стороны технологий Больших Данных поддерживаются распределенными файловыми системами Google File System, Cassandra, HBase, Lustre и ZFS, программными конструкциями MapReduce и Hadoop и множеством других решений. По оценкам экспертов, например McKinsey Institute, под влиянием Больших Данных наибольшей трансформации подвергнется сфера производства, здравоохранения, торговли, административного управления и наблюдения за индивидуальными перемещениями.
Постоянное ускорение роста объема данных является неотъемлемым элементом современных реалий. Социальные сети, мобильные устройства, данные с измерительных устройств, бизнес-информация – это лишь несколько видов источников, способных генерировать гигантские массивы данных.
В настоящее время термин Big Data (Большие данные) стал довольно распространенным. Далеко не все еще осознают то, насколько быстро и глубоко технологии обработки больших массивов данных меняют самые различные аспекты жизни общества. Перемены происходят в различных сферах, порождая новые проблемы и вызовы, в том числе и в сфере информационной безопасности, где на первом плане должны находиться такие важнейшие ее аспекты, как конфиденциальность, целостность, доступность и т. д.
К сожалению, многие современные компании прибегают к технологии Big Data, не создавая для этого надлежащей инфраструктуры, которая смогла бы обеспечить надежное хранение огромных массивов данных, которые они собирают и хранят. С другой стороны, в настоящее время стремительно развивается технология блокчейн, которая призвана решить эту и многие другие проблемы.
Что такое Big Data?
По сути, определение термина лежит на поверхности: «большие данные» означают управление очень большими объемами данных, а также их анализ. Если смотреть шире, то это информация, которая не поддается обработке классическими способами по причине ее больших объемов.
Сам термин Big Data (большие данные) появился относительно недавно. Согласно данным сервиса Google Trends , активный рост популярности термина приходится на конец 2011 года:
В 2010 году уже стали появляться первые продукты и решения, непосредственно связанные с обработкой больших данных. К 2011 году большинство крупнейших IT-компаний, включая IBM, Oracle, Microsoft и Hewlett-Packard, активно используют термин Big Data в своих деловых стратегиях. Постепенно аналитики рынка информационных технологий начинают активные исследования данной концепции.
В настоящее время этот термин приобрел значительную популярность и активно используется в самых различных сферах. Однако нельзя с уверенностью сказать, что Big Data – это какое-то принципиально новое явление – напротив, большие источники данных существуют уже много лет. В маркетинге ими можно назвать базы данных по покупкам клиентов, кредитным историям, образу жизни и т. д. На протяжении многих лет аналитики использовали эти данные, чтобы помогать компаниям прогнозировать будущие потребности клиентов, оценивать риски, формировать потребительские предпочтения и т. д.
В настоящее время ситуация изменилась в двух аспектах:
— появились более сложные инструменты и методы для анализа и сопоставления различных наборов данных;
— инструменты анализа дополнились множеством новых источников данных, что обусловлено повсеместным переходом на цифровые технологии, а также новыми методами сбора и измерения данных.
Исследователи прогнозируют, что технологии Big Data активнее всего будут использоваться в производстве, здравоохранении, торговле, госуправлении и в других самых различных сферах и отраслях.
Big Data – это не какой-либо определенный массив данных, а совокупность методов их обработки. Определяющей характеристикой для больших данных является не только их объем, но также и другие категории, характеризующие трудоемкие процессы обработки и анализа данных.
В качестве исходных данных для обработки могут выступать, например:
— логи поведения интернет-пользователей;
— Интернет вещей;
— социальные медиа;
— метеорологические данные;
— оцифрованные книги крупнейших библиотек;
— GPS-сигналы из транспортных средств;
— информация о транзакциях клиентов банков;
— данные о местонахождении абонентов мобильных сетей;
— информация о покупках в крупных ритейл-сетях и т.д.
Со временем объемы данных и количество их источников непрерывно растет, а на этом фоне появляются новые и совершенствуются уже имеющиеся методы обработки информации.
Основные принципы Big Data:
— Горизонтальная масштабируемость – массивы данных могут быть огромными и это значит, что система обработки больших данных должна динамично расширяться при увеличении их объемов.
— Отказоустойчивость – даже при сбое некоторых элементов оборудования, вся система должна оставаться работоспособной.
— Локальность данных. В больших распределенных системах данные обычно распределяются по значительному числу машин. Однако по мере возможности и в целях экономии ресурсов данные часто обрабатываются на том же сервере, что и хранятся.
Для стабильной работы всех трех принципов и, соответственно, высокой эффективности хранения и обработки больших данных необходимы новые прорывные технологии, такие как, например, блокчейн.
Для чего нужны большие данные?
Сфера применения Big Data постоянно расширяется:
— Большие данные можно использовать в медицине. Так, устанавливать диагноз пациенту можно не только опираясь на данные анализа истории болезни, но также принимая во внимание опыт других врачей, сведения об экологической ситуации района проживания больного и многие другие факторы.
— Технологии Big Data могут использоваться для организации движения беспилотного транспорта.
— Обрабатывая большие массивы данных можно распознавать лица на фото- и видеоматериалах.
— Технологии Big Data могут быть использованы ритейлерами – торговые компании могут активно использовать массивы данных из социальных сетей для эффективной настройки своих рекламных кампаний, которые могут быть максимально ориентированы под тот или иной потребительский сегмент.
— Данная технология активно используется при организации предвыборных кампаний, в том числе для анализа политических предпочтений в обществе.
— Использование технологий Big Data актуально для решений класса гарантирования доходов (RA) , которые включают в себя инструменты обнаружения несоответствий и углубленного анализа данных, позволяющие своевременно выявить вероятные потери, либо искажения информации, способные привести к снижению финансовых результатов.
— Телекоммуникационные провайдеры могут агрегировать большие данные, в том числе о геолокации; в свою очередь эта информация может представлять коммерческий интерес для рекламных агентств, которые могут использовать ее для показа таргетированной и локальной рекламы, а также для ритейлеров и банков.
— Большие данные могут сыграть важную роль при решении открытия торговой точки в определенной локации на основе данных о наличии мощного целевого потока людей.
Таким образом наиболее очевидное практическое применение технологии Big Data лежит в сфере маркетинга. Благодаря развитию интернета и распространению всевозможных коммуникационных устройств поведенческие данные (такие как число звонков, покупательские привычки и покупки) становятся доступными в режиме реального времени.
Технологии больших данных могут также эффективно использоваться в финансах, для социологических исследований и во многих других сферах. Эксперты утверждают, что все эти возможности использования больших данных являются лишь видимой частью айсберга, поскольку в гораздо больших объемах эти технологии используются в разведке и контрразведке, в военном деле, а также во всем том, что принято называть информационными войнами.
В общих чертах последовательность работы с Big Data состоит из сбора данных, структурирования полученной информации с помощью отчетов и дашбордов, а также последующего формулирования рекомендаций к действию.
Рассмотрим вкратце возможности использования технологий Big Data в маркетинге. Как известно, для маркетолога информация – главный инструмент для прогнозирования и составления стратегии. Анализ больших данных давно и успешно применяется для определения целевой аудитории, интересов, спроса и активности потребителей. Анализ больших данных, в частности, позволяет выводить рекламу (на основе модели RTB-аукциона - Real Time Bidding) только тем потребителям, которые заинтересованы в товаре или услуге.
Применение Big Data в маркетинге позволяет бизнесменам:
— лучше узнавать своих потребителей, привлекать аналогичную аудиторию в Интернете;
— оценивать степень удовлетворенности клиентов;
— понимать, соответствует ли предлагаемый сервис ожиданиям и потребностям;
— находить и внедрять новые способы, увеличивающие доверие клиентов;
— создавать проекты, пользующиеся спросом и т. д.
Например, сервис Google.trends может указать маркетологу прогноз сезонной активности спроса на конкретный продукт, колебания и географию кликов. Если сопоставить эти сведения со статистическими данными, собираемыми соответствующим плагином на собственном сайте, то можно составить план по распределению рекламного бюджета с указанием месяца, региона и других параметров.
По мнению многих исследователей, именно в сегментации и использовании Big Data заключается успех предвыборной кампании Трампа. Команда будущего президента США смогла правильно разделить аудиторию, понять ее желания и показывать именно тот месседж, который избиратели хотят видеть и слышать. Так, по мнению Ирины Белышевой из компании Data-Centric Alliance, победа Трампа во многом стала возможной благодаря нестандартному подходу к интернет-маркетингу, в основу которого легли Big Data, психолого-поведенческий анализ и персонализированная реклама.
Политтехнологи и маркетологи Трампа использовали специально разработанную математическую модель, которая позволила глубоко проанализировать данные всех избирателей США систематизировать их, сделав сверхточный таргетинг не только по географическим признаками, но также и по намерениям, интересам избирателей, их психотипу, поведенческим характеристикам и т. д. После этого маркетологи организовали персонализированную коммуникацию с каждой из групп граждан на основе их потребностей, настроений, политических взглядов, психологических особенностей и даже цвета кожи, используя практически для каждого отдельного избирателя свой месседж.
Что касается Хиллари Клинтон, то она в своей кампании использовала «проверенные временем» методы, основанные на социологических данных и стандартном маркетинге, разделив электорат лишь на формально гомогенные группы (мужчины, женщины, афроамериканцы, латиноамериканцы, бедные, богатые и т. д.).
В результате выиграл тот, кто по достоинству оценил потенциал новых технологий и методов анализа. Примечательно, что расходы на предвыборную кампанию Хиллари Клинтон были в два раза больше, чем у ее оппонента:

Данные: Pew Research
Основные проблемы использования Big Data
Помимо высокой стоимости, одним из главных факторов, тормозящих внедрение Big Data в различные сферы, является проблема выбора обрабатываемых данных: то есть определения того, какие данные необходимо извлекать, хранить и анализировать, а какие – не принимать во внимание.
Еще одна проблема Big Data носит этический характер. Другими словами возникает закономерный вопрос: можно ли подобный сбор данных (особенно без ведома пользователя) считать нарушением границ частной жизни?
Не секрет, что информация, сохраняемая в поисковых системах Google и Яндекс, позволяет IT-гигантам постоянно дорабатывать свои сервисы, делать их удобными для пользователей и создавать новые интерактивные приложения. Для этого поисковики собирают пользовательские данные об активности пользователей в интернете, IP-адреса, данные о геолокации, интересах и онлайн-покупках, личные данные, почтовые сообщения и т. д. Все это позволяет демонстрировать контекстную рекламу в соответствии с поведением пользователя в интернете. При этом обычно согласия пользователей на это не спрашивается, а возможности выбора, какие сведения о себе предоставлять, не дается. То есть по умолчанию в Big Data собирается все, что затем будет храниться на серверах данных сайтов.
Из этого вытекает следующая важная проблема, касающаяся обеспечения безопасности хранения и использования данных. Например, безопасна ли та или иная аналитическая платформа, которой потребители в автоматическом режиме передают свои данные? Кроме того, многие представители бизнеса отмечают дефицит высококвалифицированных аналитиков и маркетологов, способных эффективно оперировать большими объемами данных и решать с их помощью конкретные бизнес-задачи.
Несмотря на все сложности с внедрением Big Data, бизнес намерен увеличивать вложения в это направление. По данным исследования Gartner, лидерами инвестирующих в Big Data отраслей являются медиа, ритейл, телеком, банковский сектор и сервисные компании.
Перспективы взаимодействия технологий блокчейн и Big Data
Интеграция с Big Data несет в себе синергетический эффект и открывает бизнесу широкий спектр новых возможностей, в том числе позволяя:
— получать доступ к детализированной информации о потребительских предпочтениях, на основе которых можно выстраивать подробные аналитические профили для конкретных поставщиков, товаров и компонентов продукта;
— интегрировать подробные данные о транзакциях и статистике потребления определенных групп товаров различными категориями пользователей;
— получать подробные аналитические данные о цепях поставок и потребления, контролировать потери продукции при транспортировке (например, потери веса вследствие усыхания и испарения некоторых видов товаров);
— противодействовать фальсификациям продукции, повысить эффективность борьбы с отмыванием денег и мошенничеством и т. д.
Доступ к подробным данным об использовании и потреблении товаров в значительной мере раскроет потенциал технологии Big Data для оптимизации ключевых бизнес-процессов, снизит регуляторные риски, раскроет новые возможности монетизации и создания продукции, которая будет максимально соответствовать актуальным потребительским предпочтениям.
Как известно, к технологии блокчейн уже проявляют значительный интерес представители крупнейших финансовых институтов, включая , и т. д. По мнению Оливера Буссманна, IT-менеджера швейцарского финансового холдинга UBS, технология блокчейн способна «сократить время обработки транзакций от нескольких дней до нескольких минут».
Потенциал анализа из блокчейна при помощи технологии Big Data огромен. Технология распределенного реестра обеспечивает целостность информации, а также надежное и прозрачное хранение всей истории транзакций. Big Data, в свою очередь, предоставляет новые инструменты для эффективного анализа, прогнозирования, экономического моделирования и, соответственно, открывает новые возможности для принятия более взвешенных управленческих решений.
Тандем блокчейна и Big Data можно успешно использовать в здравоохранении. Как известно, несовершенные и неполные данные о здоровье пациента в разы увеличивают риск постановки неверного диагноза и неправильно назначенного лечения. Критически важные данные о здоровье клиентов медучреждений должны быть максимально защищенными, обладать свойствами неизменности, быть проверяемыми и не должны быть подвержены каким-либо манипуляциям.
Информация в блокчейне соответствует всем перечисленным требованиям и может служить в роли качественных и надежных исходных данных для глубокого анализа при помощи новых технологий Big Data. Помимо этого, при помощи блокчейна медицинские учреждения смогли бы обмениваться достоверными данными со страховыми компаниями, органами правосудия, работодателями, научными учреждениями и другими организациями, нуждающимися в медицинской информации.
Big Data и информационная безопасность
В широком понимании, информационная безопасность представляет собой защищенность информации и поддерживающей инфраструктуры от случайных или преднамеренных негативных воздействий естественного или искусственного характера.
В области информационной безопасности Big Data сталкивается со следующими вызовами:
— проблемы защиты данных и обеспечения их целостности;
— риск постороннего вмешательства и утечки конфиденциальной информации;
— ненадлежащее хранение конфиденциальной информации;
— риск потери информации, например, вследствие чьих-либо злонамеренных действий;
— риск нецелевого использования персональных данных третьими лицами и т. д.
Одна из главных проблем больших данных, которую призван решить блокчейн, лежит в сфере информационной безопасности. Обеспечивая соблюдение всех основных ее принципов, технология распределенного реестра может гарантировать целостность и достоверность данных, а благодаря отсутствию единой точки отказа, блокчейн делает стабильной работу информационных систем. Технология распределенного реестра может помочь решить проблему доверия к данным, а также предоставить возможность универсального обмена ими.
Информация – ценный актив, а это значит, что на первом плане должен стоять вопрос обеспечения основных аспектов информационной безопасности. Для того, чтобы выстоять в конкурентной борьбе, компании должны идти в ногу со временем, а это значит, что им нельзя игнорировать те потенциальные возможности и преимущества, которые заключают в себе технология блокчейн и инструменты Big Data.
 (1 оценок, в среднем: 5,00 из 5)
(1 оценок, в среднем: 5,00 из 5)