Посчитать количество записей в группах (созданных GROUP BY). Вычисления в sql Включение не NULL значений
есть запрос вида:
SELECT i.*, COUNT(*) AS currencies, SUM(ig.quantity) AS total, SUM(g.price * ig.quantity) AS price, c.briefly AS cname FROM invoice AS i, invoice_goods AS ig, good g LEFT JOIN currency c ON (c.id = g.currency) WHERE ig.invoice_id = i.id AND g.id = ig.good_id GROUP BY g.currency ORDER BY i.date DESC;
т.е. выбирается список заказов, в котором считаются суммарные стоимости товаров в разных валютах (валюта установлена у товара, столбец cname в результате — название валюты)
нужно в столбце результата currencies получать количество записей с одинаковым i.id , однако, эксперименты с параметрами COUNT() ни к чему не привели — всегда возвращает 1
Вопрос: возможно ли получить истинное значение в столбце currencies ? Т.е. если заказаны товары с ценами в 3х разных валютах, currencies=3 ?
Слишком большие вольности допускает MySQL по отношению к SQL однако. Что например значит i.* в контексте этого селекта? Все колонки таблицы invoice? Так как к ним не применяется никакая групповая функция, то неплохо было бы чтобы они были перечислены в GROUP BY, иначе не совсем ясен принцип группировки строк. Если необходимо получить все товары по всем заказам в разрезе валют, это одно, если необходимо получить все товары сгруппированные по валютам в разрезе каждого заказа, это совсем другое.
Исходя из вашего селекта можно предположить следующую структуру данных:
Таблица invoice:
Таблица invoice_goods:
Таблица goods:
Таблица currency:
Что вернёт ваш текущий селект? По идее он вернёт для каждого заказа N-строк по каждой валюте в которой в этом заказе есть товары. Но из-за того что в group by не указано ничего кроме g.currency, это не очевидно:), более того, колонка c.briefly тоже вносит свою лепту в неявное образование групп. Что же мы имеем в итоге, для каждой уникального сочетания i.*, g.currency и c.briefly будет сформирована группа к строчкам которой будут применены функции SUM и COUNT. То что в результате игры с параметром COUNT у вас выходила всегда 1 означает что в результирующей группе была только одна запись (т.е. группы формируются не так как вам, возможно, требуется, можете описать требования поподробнее?). Из вашего вопроса не ясно, что вы хотели бы узнать - сколько разных валют учавствовало в заказе или сколько заказов было в данной валюте? В первом случае возможны несколько вариантов всё зависит от возможностей mySQL, во втором надо по-другому написать селект выражение.
Слишком большие вольности допускает MySQL по отношению к SQL однако. Что например значит i.* в контексте этого селекта? Все колонки таблицы invoice?
Да, именно. Но большой роли это не играет, т.к. полезных в данном случае среди них (колонок) нет. Пускай i.* будет i.id . Для определённости.
Что вернёт ваш текущий селект? По идее он вернёт для каждого заказа N-строк по каждой валюте в которой в этом заказе есть товары. Но из-за того что в group by не указано ничего кроме g.currency, это не очевидно:),
Именно так.
Вернёт он следующее (в этом примере из i я выбираю только id , а не все столбцы):
| id | currencies | total | price | cname |
|---|---|---|---|---|
| 33 | 1 | 1.00 | 198.00 | BF |
| 33 | 1 | 4.00 | 1548.04 | РУБ |
более того, колонка c.briefly тоже вносит свою лепту в неявное образование групп.
Каким образом? По c.id=g.currency делается соединение таблиц, а группировка по g.currency .
То что в результате игры с параметром COUNT у вас выходила всегда 1 означает что в результирующей группе была только одна запись
Нет, группа строилась из 1й
записи. Насколько я это понял, COUNT() возвращает 1 именно поэтому (ведь столбцы, которые в группе отличаются (правда, кроме столбца валют), создаются аггрегатными функциями).
(т.е. группы формируются не так как вам, возможно, требуется, можете описать требования поподробнее?).
Группы формируются так как надо, каждая группа -- это сумарная стоимость товаров в каждой валюте . Однако, мне, помимо того, нужно посчитать, сколько же элементов в этой группе .
Из вашего вопроса не ясно, что вы хотели бы узнать - сколько разных валют учавствовало в заказе или сколько заказов было в данной валюте?
Да уж, заработался немного. Как раз первое.
dmig[досье]
Под "неявным" участием в образованием группы я подразумеваю, что если колонка не указана в GROUP BY, и при этом НЕ является аргументом групповой функции, то результат селекта будет идентичен тому, как если бы эта колонока БЫЛА указана в GROUP BY. Ваш селект, и селект приведённый ниже выведут абсолютно одинаковый результат (не обращайте внимания на join"ы, я просто привёл их к единому формату записи):
Select i.id id, count(*) currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly
Получается что в каждой строке результирующей выборки есть одна, и только одна валюта (если бы это было по другому, то и строк было бы две). О количестве каких элементов в таком случае речь? О пунктах заказа? Тогда ваш селект абсолютно правильный, просто по данной валюте, в данном заказе только один пункт.
Давайте рассмотрим схему данных:
- В одном заказе множество пунктов (строк),так?
- Каждый пункт это товар в справочнике goods, так?
- Каждый товар имеет определённую (и только одну) валюту, это следует из c.id = g.currency, так?
Сколько валют в заказе? Столько сколько в нём пунктов с РАЗНЫМИ валютами.
Складывать g.price * ig.quantity имеет смысл только для пунктов в одной валюте;) (хотя километры с часами, тоже складывать можно:) Так что же вас не устраивает!? Вы утверждаете, что вам надо сколько разных валют учавствовало в заказе
и в таком случае сделать это в рамках этого же селекта без всяческих ухищрений (которые скорее всего не потянет MySQL) не получится;(
Я к сожалению не знаток MySQL. В oracle сделать это одним селектом можно, но поможет ли вам такой совет? Вряд ли;)
# В одном заказе множество пунктов (строк),так?
# Каждый пункт это товар в справочнике goods, так?
# Каждый товар имеет определённую (и только одну) валюту, это следует из c.id = g.currency, так?
Так.
Один заказ: одна запись в таблице invoice, ей соответствуют n(>0) записей в invoice_goods, каждой из которых соответствует 1 запись в таблице goods, запись "валюта" в каждой из которых, в свою очередь, соответствует 1й записи в таблице currency (LEFT JOIN — на случай редактирования справочника валют кривыми руками — таблицы типа MyISAM не поддерживают внешних ключей).
Сколько валют в заказе? Столько сколько в нём пунктов с РАЗНЫМИ валютами.
Да, именно так.
Складывать g.price * ig.quantity имеет смысл только для пунктов в одной валюте;) (хотя километры с часами, тоже складывать можно:)
Именно поэтому делается группировка по id валюты (g.currency).
В oracle сделать это одним селектом можно, но поможет ли вам такой совет?
М.б.
Я немного общался с Oracle, с pl/sql знаком.
Вариант №1.
Select a.*, count(*) over (partition by a.id) currencies from (select i.id id, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly) a
Это использует т.н. analytic function. С вероятностью 99% НЕ работает в MySQL.
Вариант №2.
Создаётся функция, countCurrencies например, которая по id заказа возвращает кол-во валют которое в нём учавствовало и тогда:
Select i.id id, countCurrencies(i.id) currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) group by i.id, c.briefly, countCurrencies(i.id)
Может прокатить... но будет вызываться для каждой валюты каждого заказа. Не знаю даёт ли MySQL делать GROUP BY по функции...
Вариант №3
Select i.id id, agr.cnt currencies, sum(ig.quantity) total, SUM(g.price * ig.quantity) price, c.briefly cname FROM invoice i join invoice_goods ig on (ig.invoice_id = i.id) join good g on (g.id = ig.good_id) LEFT OUTER JOIN currency c ON (c.id = g.currency) left outer join (select ii.id, count(distinct gg.currency) cnt from invoice ii, invoce_goods iig, good gg where ii.id = iig.invoice_id and gg.id = iig.good_id group by ii.id) agr on (i.id = agr.id) group by i.id, c.briefly, agr.cnt
Наверное самый правильный... и вполне возможно самый рабочий вариант из всех.
Самый быстрый это Вариант №1. №2 самый неэффективный, т.к. чем больше валют в заказе, тем чаще они считаются.
№3 тоже в принципе не лучший по скорости, но по крайней мере можно положится на кэширование внутри СУБД.
результатом всех трёх селектов будет следующее:
| id | currencies | total | price | cname | ||||
|---|---|---|---|---|---|---|---|---|
| 33 | 2 | 1.00 | 198.00 | BF | ||||
| 33 | 2 | 4.00 | 1548.04 | РУБ | ||||
для одного и того же id цифра в колонке currencies будет всегда одинаковая, это то что вам надо?
SQL - Урок 8. Группировка записей и функция COUNT()
Давайте вспомним, какие сообщения и в каких темах у нас имеются. Для этого можно воспользоваться привычным запросом: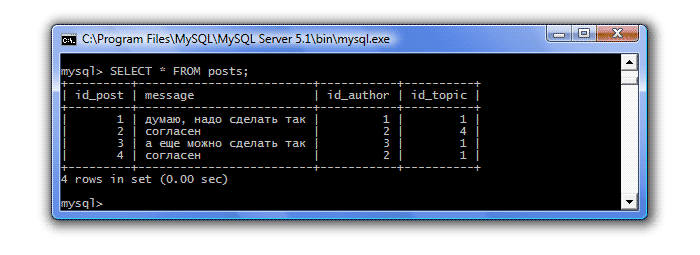
А что, если нам надо лишь узнать сколько сообщений на форуме имеется. Для этого можно воспользоваться встроенной функцией COUNT() . Эта функция подсчитывает число строк. Причем, если в качестве аргумента этой функции выступает *, то подсчитываются все строки таблицы. А если в качестве аргумента указывается имя столбца, то подсчитываются только те строки, которые имеют значение в указанном столбце.
В нашем примере оба аргумента дадут одинаковый результат, т.к. все столбцы таблицы имеют тип NOT NULL. Давайте напишем запрос, используя в качестве аргумента столбец id_topic:
SELECT COUNT(id_topic) FROM posts;

Итак, в наших темах имеется 4 сообщения. Но что, если мы хотим узнать сколько сообщений имеется в каждой теме. Для этого нам понадобится сгруппировать наши сообщения по темам и вычислить для каждой группы количество сообщений. Для группировки в SQL используется оператор GROUP BY . Наш запрос теперь будет выглядеть так:
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic;
Оператор GROUP BY указывает СУБД сгруппировать данные по столбцу id_topic (т.е. каждая тема - отдельная группа) и для каждой группы подсчитать количество строк:
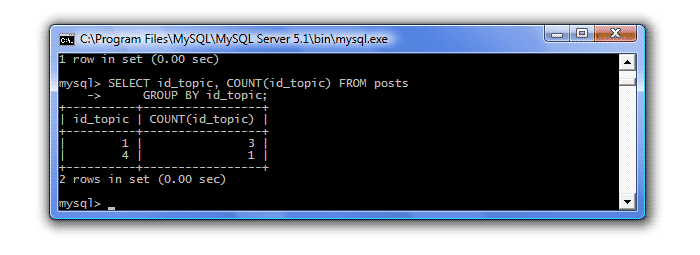
Ну вот, в теме с id=1 у нас 3 сообщения, а с id=4 - одно. Кстати, если бы в поле id_topic были возможны отсутствия значений, то такие строки были бы объединены в отдельную группу со значением NULL.
Предположим, что нас интересуют только те группы, в которых больше двух сообщений. В обычном запросе мы указали бы условие с помощью оператора WHERE , но этот оператор умеет работать только со строками, а для групп те же функции выполняет оператор HAVING :
SELECT id_topic, COUNT(id_topic) FROM posts GROUP BY id_topic HAVING COUNT(id_topic) > 2;
В результате имеем:

В уроке 4 мы рассматривали, какие условия можно задавать оператором WHERE , те же условия можно задавать и оператором HAVING , только надо запомнить, что WHERE фильтрует строки, а HAVING - группы.
Итак, сегодня мы узнали, как создавать группы и как подсчитать количество строк в таблице и в группах. Вообще вместе с оператором GROUP BY можно использовать и другие встроенные функции, но их мы будем изучать позже.
ВЫЧИСЛЕНИЯ
Итоговые функции
В выражениях SQL-запросов нередко требуется выполнить предварительную обработку данных. С этой целью используются специальные функции и выражения.
Довольно часто требуется узнать, сколько записей соответствует тому или иному запросу, какова сумма значений некоторого числового столбца, его максимальное, минимальное и среднее значения. Для этого служат так называемые итоговые (статистические, агрегатные) функции. Итоговые функции обрабатывают наборы записей, заданные, например, выражением WHERE. Если их включить в список столбцов, следующий за оператором SELECT, то результатная таблица будет содержать не только столбцы таблицы базы данных, но и значения, вычисленные с помощью этих функций. Далее приведен список итоговых функций .
- COUNT (параметр ) возвращает количество записей, указанных в параметре. Если требуется получить количество всех записей, то в качестве параметра следует указать символ звездочки (*). Если в качестве параметра указать имя столбца, то функция вернет количество записей, в которых этот столбец имеет значения, отличные от NULL. Чтобы узнать, сколько различных значений содержит столбец, перед его именем следует указать ключевое слово DISTINCT. Например:
SELECT COUNT(*) FROM Клиенты;
SELECT COUNT(Сумма_заказа) FROM Клиенты;
SELECT COUNT(DISTINCT Сумма_заказа) FROM Клиенты;
Попытка выполнить следующий запрос приведет к сообщению об ошибке:
SELECT Регион , COUNT(*) FROM Клиенты ;
- SUM (параметр ) возвращает сумму значений указанного в параметре столбца. Параметр может представлять собой и выражение, содержащее имя столбца. Например:
SELECT SUM (Сумма_заказа) FROM Клиенты;
Данное SQL-выражение возвращает таблицу, состоящую из одного столбца и одной записи и содержащую сумму всех определенных значений столбца Сумма_заказа из таблицы Клиенты.
Допустим, что в исходной таблице значения столбца Сумма_заказа выражены в рублях, а нам требуется вычислить общую сумму в долларах. Если текущий обменный курс равен, например, 27,8, то получить требуемый результат можно с помощью выражения:
SELECT SUM (Сумма_заказа*27.8) FROM Клиенты;
- AVG (параметр ) возвращает среднее арифметическое всех значений указанного в параметре столбца. Параметр может представлять собой выражение, содержащее имя столбца. Например:
SELECT AVG (Сумма_заказа) FROM Клиенты;
SELECT AVG (Сумма_заказа*27.8) FROM Клиенты
WHERE Регион <> "Северо_3апад";
- МАХ (параметр ) возвращает максимальное значение в столбце, указанном в параметре. Параметр может также представлять собой выражение, содержащее имя столбца. Например:
SELECT МАХ(Сумма__заказа) FROM Клиенты;
SELECT МАХ(Сумма_заказа*27.8) FROM Клиенты
W HERE Регион <> "Северо_3апад";
- MIN (параметр ) возвращает минимальное значение в столбце, указанном в параметре. Параметр может представлять собой выражение, содержащее имя столбца. Например:
SELECT MIN(Сумма_заказа) FROM Клиенты;
SELECT MIN (Сумма__заказа*27 . 8) FROM Клиенты
W HERE Регион <> "Северо_3апад";
На практике нередко требуется получить итоговую таблицу, содержащую суммарные, усредненные, максимальные и минимальные значения числовых столбцов. Для этого следует использовать группировку (GROUP BY) и итоговые функции.
SELECT Регион, SUM (Сумма_заказа) FROM Клиенты
GROUP BY Регион;
Результатная таблица для данного запроса содержит имена регионов и итоговые (общие) суммы заказов всех клиентов из соответствующих регионов (рис. 5).
Теперь рассмотрим запрос на получение всех итоговых данных по регионам:
SELECT Регион, SUM (Сумма_заказа), AVG (Сумма_заказа), МАХ(Сумма_заказа), MIN (Сумма_заказа)
FROM Клиенты
GROUP BY Регион;
Исходная и результатная таблицы показаны на рис. 8. В примере только Северо-Западный регион представлен в исходной таблице более чем одной записью. Поэтому в результатной таблице для него различные итоговые функции дают различные значения.
Рис. 8. Итоговая таблица сумм заказов по регионам
При использовании итоговых функций в списке столбцов в операторе SELECT заголовки соответствующих им столбцов в результатной таблице имеют вид Expr1001, Expr1002 и т.д. (или что-нибудь аналогичное, в зависимости от реализации SQL). Однако заголовки для значений итоговых функций и других столбцов вы можете задавать по своему усмотрению. Для этого достаточно после столбца в операторе SELECT указать выражение вида:
AS заголовок_столбца
Ключевое слово AS (как) означает, что в результатной таблице соответствующий столбец должен иметь заголовок, указанный после AS. Назначаемый заголовок еще называют псевдонимом. В следующем примере (рис. 9) задаются псевдонимы для всех вычисляемых столбцов:
SELECT Регион,
SUM (Сумма_заказа) AS [Общая сумма заказа],
AVG (Сумма_заказа) AS [Средняя сумма заказа],
МАХ(Сумма_заказа) AS Максимум,
MIN (Сумма_заказа) AS Минимум,
FROM Клиенты
GROUP BY Регион;

Рис. 9. Итоговая таблица сумм заказов по регионам с применением псевдонимов столбца
Псевдонимы, состоящие из нескольких слов, разделенных пробелами, заключаются в квадратные скобки.
Итоговые функции можно использовать в выражениях SELECT и HAVING, но их нельзя применять в выражении WHERE. Oneратор HAVING аналогичен оператору WHERE, но в отличие от WHERE он отбирает записи в группах.
Допустим, требуется определить, в каких регионах более одного клиента. С этой целью можно воспользоваться таким запросом:
SELECT Регион , Count(*)
FROM Клиенты
GROUP BY Регион HAVING COUNT(*) > 1;
Функции обработки значений
При работе с данными часто приходится их обрабатывать (преобразовывать к нужному виду): выделить в строке некоторую подстроку, удалить ведущие и заключительные пробелы, округлить число, вычислить квадратный корень, определить текущее время и т. п. В SQL имеются следующие три типа функций:
- строковые функции;
- числовые функции;
- функции даты-времени.
Строковые функции
Строковые функции принимают в качестве параметра строку и возвращают после ее обработки строку или NULL.
- SUBSTRING (строка FROM начало ) возвращает подстроку, получающуюся из строки, которая указана в качестве параметра строка . Подстрока начинается с символа, порядковый номер которого указан в параметре начало, и имеет длину, указанную в параметре длина. Нумерация символов строки ведется слева направо, начиная с 1. Квадратные скобки здесь указывают лишь на то, что заключенное в них выражение не является обязательным. Если выражение FOR длина не используется, то возвращается подстрока от начало и до конца исходной строки. Значения параметров начало и длина должны выбираться так, чтобы искомая подстрока действительно находилась внутри исходной строки. В противном случае функция SUBSTRING вернет NULL.
Например:
SUBSTRING ("Дорогая Маша!" FROM 9 FOR 4) возвращает "Маша";
SUBSTRING ("Дорогая Маша! " FROM 9) возвращает "Маша! ";
SUBSTRING("Дорогая Маша! " FROM 15) возвращает NULL.
Использовать эту функцию в SQL-выражении можно, например, так:
SELECT * FROM Клиенты
WHERE SUBSTRING(Регион FROM 1 FOR 5) = "Север";
- UPPER (строка ) переводит все символы указанной в параметре строки в верхний регистр.
- LOWER (строка ) переводит все символы указанной в параметре строки в нижний регистр.
- TRIM (LEADING | TRAILING | BOTH ["символ"] FROM строка ) удаляет ведущие (LEADING), заключительные (TRAILING) или те и другие (BOTH) символы из строки. По умолчанию удаляемым символом является пробел (" "), поэтому его можно не указывать. Чаще всего эта функция используется именно для удаления пробелов.
Например:
TRIM (LEADING " " FROM "город Санкт-Петербург") вращает " город Санкт-Петербург ";
TRIM(TRALING " " FROM "город Санкт-Петербург") возвращает "город Санкт-Петербург";
TRIM (BOTH " " FROM " город Санкт-Петербург ") возвращает "город Санкт-Петербург";
TRIM(BOTH FROM " город Санкт-Петербург ") возвращает "город Санкт-Петербург";
TRIM(BOTH "г" FROM "город Санкт-Петербург") возвращает "ород Санкт-Петербур".
Среди этих функций наиболее часто используемые - SUBSTRING() И TRIM().
Числовые функции
Числовые функции в качестве параметра могут принимать данные не только числового типа, но возвращают всегда число или NULL (неопределенное значение).
- POSITION (целеваяСтрока IN строка ) ищет вхождение целевой строки в указанную строку. В случае успешного поиска возвращает номер положения ее первого символа, иначе 0. Если целевая строка имеет нулевую длину (например, строка " "), то функция возвращает 1. Если хотя бы один из параметров имеет значение NULL, то возвращается NULL. Нумерация символов строки ведется слева направо, начиная с 1.
Например:
POSITION ("e" IN "Привет всем") возвращает 5;
POSITION ("всeм" IN "Привет всем") возвращает 8;
POSITION (" " Привет всем") возвращает 1;
POSITION("Привет!" IN "Привет всем") возвращает 0.
В таблице Клиенты (см. рис. 1) столбец Адрес содержит, кроме названия города, почтовый индекс, название улицы и другие данные. Возможно, вам потребуется выбрать записи о клиентах, проживающих в определенном городе. Так, если требуется выбрать записи, относящиеся к клиентам, проживающим в Санкт-Петербурге, то можно воспользоваться следующим выражением SQL-запроса:
SELECT * FROM Клиенты
WHERE POSITION (" Санкт - Петербург " IN Адрес ) > 0;
Заметим, что этот простой запрос на выборку данных можно сформулировать иначе:
SELECT * FROM Клиенты
WHERE Адрес LIKE " %Петербург% ";
- EXTRACT (параметр ) извлекает элемент из значения типа дата-время или из интервала. Например:
EXTRACT (MONTH FROM DATE "2005-10-25") возвращает 10.
- CHARACTER_LENGTH (строка ) возвращает количество символов в строке.
Например:
CHARACTER_LENGTH("Привет всем") возвращает 11.
- OCTET_LENGTH (строка ) возвращает количество октетов (байтов) в строке. Каждый символ латиницы или кириллицы представляется одним байтом, а символ китайского алфавита двумя байтами.
- CARDINALITY (параметр ) принимает в качестве параметра коллекцию элементов и возвращает количество элементов в коллекции (кардинальное число). Коллекция может быть, например, массивом или мультимножеством, содержащим элементы различных типов.
- ABS (число ) возвращает абсолютное значение числа. Например:
ABS (-123) возвращает 123;
ABS (2 - 5) возвращает 3.
- МО D (число1, число2 ) возвращает остаток от целочисленного деления первого числа на второе. Например:
MOD (5, з) возвращает 2;
MOD (2, з) возвращает 0.
- LN (число ) возвращает натуральный логарифм числа.
- ЕХР (число ) возвращает е число (основание натурального логарифма в степени число).
- POWER (число1, число2 ) возвращает число1 число2 (число1 в степени число2).
- SQRT (число ) возвращает квадратный корень из числа.
- FLOOR (число ) возвращает наибольшее целое число, не превышающее заданное параметром (округление в меньшую сторону). Например:
FLOOR (5.123) возвращает 5.0.
- CEIL (число ) или CEILING (число ) возвращает наименьшее целое число, которое не меньше заданного параметром округление в большую сторону). Например:
CEIL (5.123) возвращает 6. 0.
- WIDTH_BUCKET (число1, число2, числоЗ, число4) возвращает целое число в диапазоне между 0 и число4 + 1. Параметры число2 и числоЗ задают числовой отрезок, разделенный на равновеликие интервалы, количество которых задается параметром число 4. Функция определяет номер интервала, в который попадает значение число1. Если число1 находится за пределами заданного диапазона, то функция возвращает 0 или число 4 + 1. Например:
WIDTH_BUCKET(3.14, 0, 9, 5) возвращает 2.
Функции даты-времени
В языке SQL имеются три функции, которые возвращают текущие дату и время.
- CURRENT_DATE возвращает текущую дату (тип DATE).
Например: 2005-06-18.
- CURRENT_TIME (число ) возвращает текущее время (тип TIME). Целочисленный параметр указывает точность представления секунд. Например, при значении 2 секунды будут представлены с точностью до сотых (две цифры в дробной части):
12:39:45.27.
- CURRENT_TIMESTAMP (число ) возвращает дату и время (тип TIMESTAMP). Например, 2005-06-18 12:39:45.27. Целочисленный параметр указывает точность представления секунд.
Обратите внимание, что дата и время, возвращаемые этими функциями, имеют не символьный тип. Если требуется представить их в виде символьных строк, то для этого следует использовать функцию преобразования типа CAST ().
Функции даты-времени обычно применяются в запросах на вставку, обновление и удаление данных. Например, при записи сведений о продажах в специально предусмотренный для этого столбец вносятся текущие дата и время. После подведения итогов за месяц или квартал, данные о продажах за отчетный период можно удалить.
Вычисляемые выражения
Вычисляемые выражения строятся из констант (числовых, строковых, логических), функций, имен полей и данных других типов путем соединения их арифметическими, строковыми, логическими и другими операторами. В свою очередь, выражения могут быть объединены посредством операторов в более сложные (составные) выражения. Для управления порядком вычисления выражений используются круглые скобки.
Логические операторы AND, OR и NOT и функции были рассмотрены ранее.
Арифметические операторы:
- + сложение;
- - вычитание;
- * умножение;
- / деление.
Строковый оператор только один оператор конкатенации или склейки строк (| |). В некоторых реализациях SQL (например, Microsoft Access) вместо (| |) используется символ (+). Оператор конкатенации приписывает вторую строку к концу первой пример, выражение:
"Саша" | | "любит" | | " Машу"
вернет в качестве результата строку " Сашалюбит Машу".
При составлении выражений необходимо следить, чтобы операнды операторов имели допустимые типы. Например, выражение: 123 + "Саша" недопустимо, поскольку арифметический оператор сложения применяется к строковому операнду.
Вычисляемые выражения могут находиться после оператора SELECT, а также в выражениях условий операторов WHERE и HAVI NG .
Рассмотрим несколько примеров.
Пусть таблица Продажи содержит столбцы Тип_товара, Количество и Цена, а нам требуется знать выручку для каждого типа товара. Для этого достаточно в список столбцов после оператора SELECT включить выражение Количество*Цена:
SELECT Тип_товара, Количество, Цена, Количество*Цена AS
Итого FROM Продажи;
Здесь используется ключевое слово AS (как) для задания псевдонима столбца с вычисляемыми данными.
На рис. 10 показаны исходная таблица Продажи и результатная таблица запроса.

Рис. 10. Результат запроса с вычислением выручки по каждому типу товара
Если требуется узнать общую выручку от продажи всех товаров, то достаточно применить следующий запрос:
SELECT SUM (Количество*Цена) FROM Продажи;
Следующий запрос содержит вычисляемые выражения и в списке столбцов, и в условии оператора WHERE. Он выбирает из таблицы продажи те товары, выручка от продажи которых больше 1000:
SELECT Тип_товара, Количество*Цена AS Итого
FROM Продажи
WHERE Количество*Цена > 1000;
Предположим, что требуется получить таблицу, в которой два столбца:
Товар, содержащий тип товара и цену;
Итого, содержащий выручку.
Поскольку предполагается, что в исходной таблице продажи столбец Тип_товара является символьным (тип CHAR), а столбец Цена числовой, то при объединении (склейке) данных из этих столбцов необходимо выполнить приведение числового типа к символьному с помощью функции CAST (). Запрос, выполняющий это задание, выглядит так (рис. 11):
SELECT Тип_товара | | " (Цена: " | | CAST(Цена AS CHAR(5)) | | ")" AS Товар, Количество*Цена AS Итого
FROM Продажи;

Рис. 11. Результат запроса с объединением разнотипных данных в одном столбце
Примечание. В Microsoft Access аналогичный запрос будет иметь следующий вид:
SELECT Тип_товара + " (Цена: " + C Str (Цена) + ")" AS Товар,
Количество*Цена AS Итого
FROM Продажи;
Условные выражения с оператором CASE
В обычных языках программирования имеются операторы условного перехода, которые позволяют управлять вычислительным процессом в зависимости от того, выполняется или нет некоторое условие. В языке SQL таким оператором является CASE (случай, обстоятельство, экземпляр ). В SQL:2003 этот оператор возвращает значение и, следовательно, может использоваться в выражениях. Он имеет две основные формы, которые мы рассмотрим в данном разделе.
Оператор CASE со значениями
Оператор CASE со значениями имеет следующий синтаксис:
CASE проверяемое_значение
WHEN значение1 THEN результат1
WHEN значение2 THEN резулътат2
. . .
WHEN значением N THEN результат N
ELSE результатХ
В случае, когда проверяемое_значение равно значение1 , оператор CASE возвращает значение результат1 , указанное после ключевого слова THEN (то). В противном случае проверяемое_значение сравнивается с значение2 , и если они равны, то возвращается значение результат2. В противном случае проверяемое значение сравнивается со следующим значением, указанным после ключевого слова WHEN (когда) и т. д. Если проверяемое_значение не равно ни одному из таких значений, то возвращается значение результат X , указанное после ключевого слова ELSE (иначе).
Ключевое слово ELSE не является обязательным. Если оно отсутствует и ни одно из значений, подлежащих сравнению, не равно проверяемому значению, то оператор CASE возвращает NULL.
Допустим, на основе таблицы Клиенты (см. рис. 1) требуется получить таблицу, в которой названия регионов заменены их кодовыми номерами. Если в исходной таблице различных регионов не слишком много, то для решения данной задачи удобно воспользоваться запросом с оператором CASE:
SELECT Имя , Адрес ,
CASE Регион
WHEN " Москва " THEN "77"
WHEN "Тверская область" THEN "69"
. . .
ELSE Регион
AS Код региона
FROM Клиенты;
Оператор CASE с условиями поиска
Вторая форма оператора CASE предполагает его использование при поиске в таблице тех записей, которые удовлетворяют определенному условию:
CASE
WHEN условие1 THEN результат1
WHEN уоловие2 THEN результат2
. . .
WHEN условие N THEN результат N
ELSE результатХ
Оператор CASE проверяет, истинно ли условие1 для первой записи в наборе, определенном оператором WHERE, или во всей таблице, если WHERE отсутствует. Если да, то CASE возвращает значение результат1. В противном случае для данной записи проверяется условие2. Если оно истинно, то возвращается значение результат2 и т. д. Если ни одно из условий не выполняется, то возвращается значение результат X , указанное после ключ го слова ELSE.
Ключевое слово ELSE не является обязательным. Если оно отсутствует и ни одно из условий не выполняется, оператор CASE вращает NULL. После того как оператор, содержащий CASE, выполнится для первой записи, происходит переход к следующей записи. Так продолжается до тех пор, пока не будет обработан весь набор записей.
Предположим, в таблице книги (Название, Цена) столбец имеет значение NULL, если соответствующей книги нет в наличии. Следующий запрос возвращает таблицу, в которой вместо NULL отображается текст "Нет в наличии":
SELECT Название,
CASE
WHEN Цена IS NULL THEN " Нет в наличии "
ELSE CAST(Цена AS CHAR(8))
AS Цена
FROM Книги;
Все значения одного и того же столбца должны иметь одинаковые типы. Поэтому в данном запросе используется функция преобразования типов CAST для приведения числовых значений столбца Цена к символьному типу.
Обратите внимание, что вместо первой формы оператора CASE всегда можно использовать вторую:
CASE
WHEN проверяемое_значение = значение1 THEN результат1
WHEN проверяемое_значение = значение2 THEN результат2
. . .
WHEN проверяемое_значение = значение N THEN peзyльтaтN
ELSE резулътатХ
Функции NULLIF и COALESCE
В ряде случаев, особенно в запросах на обновление данных (оператор UPDATE), удобно использовать вместо громоздкого оператора CASE более компактные функции NULLIF () (NULL, если) и COALESCE() (объединять).
Функция NULLIF (значение1, значение2 ) возвращает NULL, если значение первого параметра соответствует значению второго параметра, в случае несоответствия возвращается значение первого параметра без изменений. То есть если равенство значение1 = значение2 выполняется, то функция возвращает NULL, иначе значение значение1.
Данная функция эквивалентна оператору CASE в следующих двух формах:
- CASE значение1
WHEN значение2 THEN NULL
ELSE значение1
- CASE
WHEN значение1 = значение2 THEN NULL
ELSE значение1
Функция COALESCE(значение1, значение2, ... , значение N ) принимает список значений, которые могут быть как определенными, так и неопределенными (NULL). Функция возвращает определенное значение из списка или NULL, если все значения не определены.
Данная функция эквивалентна следующему оператору CASE:
CASE
WHEN значение 1 IS NOT NULL THEN значение 1
WHEN значение 2 IS NOT NULL THEN значение 2
. . .
WHEN значение N IS NOT NULL THEN значение N
ELSE NULL
Предположим, что в таблице Книги (Название, Цена) столбец Цена имеет значение NULL, если соответствующей книги нет в наличии. Следующий запрос возвращает таблицу, в которой вместо NULL отображается текст "Нет в наличии":
SELECT Название, COALESCE (CAST(Цена AS CHAR(8)),
"Нет в наличии") AS Цена
FROM Книги;
 (1 оценок, в среднем: 5,00 из 5)
(1 оценок, в среднем: 5,00 из 5)